K-means算法原理與R語言實例
聚類是將相似對象歸到同一個簇中的方法���,這有點像全自動分類�����。簇內的對象越相似��,聚類的效果越好����。支持向量機��、神經網絡所討論的分類問題都是有監督的學習方式����,現在我們所介紹的聚類則是無監督的�����。其中���,K均值(K-means)是最基本���、最簡單的聚類算法�����。
在K均值算法中���,質心是定義聚類原型(也就是機器學習獲得的結果)的核心����。在介紹算法實施的具體過程中��,我們將演示質心的計算方法����。而且你將看到除了第一次的質心是被指定的以外��,此后的質心都是經由計算均值而獲得的�����。
首先�,選擇K個初始質心(這K個質心并不要求來自于樣本數據集)����,其中K是用戶指定的參數�����,也就是所期望的簇的個數�����。每個數據點都被收歸到距其最近之質心的分類中��,而同一個質心所收歸的點集為一個簇���。然后�,根據本次分類的結果����,更新每個簇的質心�。重復上述數據點分類與質心變更步驟��,直到簇內數據點不再改變���,或者等價地說��,直到質心不再改變���。
基本的K均值算法描述如下:
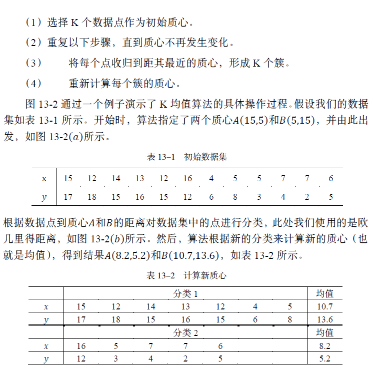
根據數據點到新質心的距離��,再次對數據集中的數據進行分類���,如圖13-2(c)所示����。然后����,算法根據新的分類來計算新的質心�����,并再次根據數據點到新質心的距離�,對數據集中的數據進行分類��。結果發現簇內數據點不再改變����,所以算法執行結束����,最終的聚類結果如圖13-2(d)所示���。
對于距離函數和質心類型的某些組合�����,算法總是收斂到一個解��,即K均值到達一種狀態���,聚類結果和質心都不再改變��。但為了避免過度迭代所導致的時間消耗���,實踐中���,也常用一個較弱的條件替換掉“質心不再發生變化”這個條件��。例如����,使用“直到僅有1%的點改變簇”���。
盡管K均值聚類比較簡單�����,但它也的確相當有效�����。它的某些變種甚至更有效�����, 并且不太受初始化問題的影響���。但K均值并不適合所有的數據類型����。它不能處理非球形簇����、不同尺寸和不同密度的簇��,盡管指定足夠大的簇個數時它通??梢园l現純子簇���。對包含離群點的數據進行聚類時�����,K均值也有問題�。在這種情況下���,離群點檢測和刪除大有幫助��。K均值的另一個問題是����,它對初值的選擇是敏感的����,這說明不同初值的選擇所導致的迭代次數可能相差很大����。此外����,K值的選擇也是一個問題����。顯然�,算法本身并不能自適應地判定數據集應該被劃分成幾個簇�。最后��,K均值僅限于具有質心(均值)概念的數據���。一種相關的K中心點聚類技術沒有這種限制���。在K中心點聚類中�,我們每次選擇的不再是均值����,而是中位數�����。這種算法實現的其他細節與K均值相差不大����,我們不再贅述���。
最后我們給出一個實際應用的例子����。(代碼采用我最喜歡用做數據挖掘的R語言來實現)
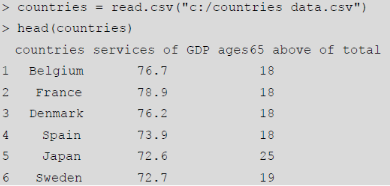
一組來自世界銀行的數據統計了30個國家的兩項指標��,我們用如下代碼讀入文件并顯示其中最開始的幾行數據����?���?梢?���,數據共分三列��,其中第一列是國家的名字�,該項與后面的聚類分析無關��,我們更關心后面兩列信息�。第二列給出的該國第三產業增加值占GDP的比重���,最后一列給出的是人口結構中年齡大于等于65歲的人口(也就是老齡人口)占總人口的比重���。
為了方便后續處理�,下面對讀入的數據庫進行一些必要的預處理����,主要是調整列標簽�,以及用國名替換掉行標簽(同時刪除包含國名的列)����。

如果你繪制這些數據的散點圖�����,不難發現這些數據大致可以分為兩組����。事實上��,數據中有一半的國家是OECD成員國�����,而另外一半則屬于發展中國家(包括一些東盟國家���、南亞國家和拉美國家)����。所以我們可以采用下面的代碼來進行K均值聚類分析�����。
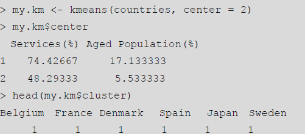
對于聚類結果�,限于篇幅我們仍然只列出了最開始的幾條����。但是如果用圖形來顯示的話����,可能更易于接受��。下面是示例代碼�����。

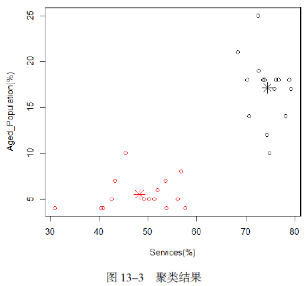
上述代碼的執行結果如圖13-3所示�。
另外一種與k-means非常類似的算法是k-median算法��。此處已經無需再詳細介紹k-中值算法的細節了����,基本上和k-means一樣�,只是把所有均值出現的地方換成中值而已��。這個思想看起好像很不起眼����,但是你還別說��,k-median算法還真的存在�����,而且是k-means算法的一個重要補充和改進��。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
