機器學習算法與Python實踐之(一)k近鄰(KNN)
一����、kNN算法分析
K最近鄰(k-Nearest Neighbor�,KNN)分類算法可以說是最簡單的機器學習算法了�。它采用測量不同特征值之間的距離方法進行分類���。它的思想很簡單:如果一個樣本在特征空間中的k個最相似(即特征空間中最鄰近)的樣本中的大多數屬于某一個類別��,則該樣本也屬于這個類別�����。
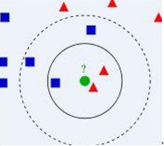
比如上面這個圖����,我們有兩類數據���,分別是藍色方塊和紅色三角形����,他們分布在一個上圖的二維中間中����。那么假如我們有一個綠色圓圈這個數據��,需要判斷這個數據是屬于藍色方塊這一類��,還是與紅色三角形同類�。怎么做呢��?我們先把離這個綠色圓圈最近的幾個點找到���,因為我們覺得離綠色圓圈最近的才對它的類別有判斷的幫助���。那到底要用多少個來判斷呢�?這個個數就是k了���。如果k=3���,就表示我們選擇離綠色圓圈最近的3個點來判斷��,由于紅色三角形所占比例為2/3�,所以我們認為綠色圓是和紅色三角形同類����。如果k=5��,由于藍色四方形比例為3/5�,因此綠色圓被賦予藍色四方形類�����。從這里可以看到����,k的值還是很重要的����。
KNN算法中���,所選擇的鄰居都是已經正確分類的對象���。該方法在定類決策上只依據最鄰近的一個或者幾個樣本的類別來決定待分樣本所屬的類別����。由于KNN方法主要靠周圍有限的鄰近的樣本���,而不是靠判別類域的方法來確定所屬類別的����,因此對于類域的交叉或重疊較多的待分樣本集來說���,KNN方法較其他方法更為適合����。
該算法在分類時有個主要的不足是�,當樣本不平衡時��,如一個類的樣本容量很大�,而其他類樣本容量很小時�����,有可能導致當輸入一個新樣本時����,該樣本的K個鄰居中大容量類的樣本占多數��。因此可以采用權值的方法(和該樣本距離小的鄰居權值大)來改進�。該方法的另一個不足之處是計算量較大��,因為對每一個待分類的文本都要計算它到全體已知樣本的距離����,才能求得它的K個最近鄰點�。目前常用的解決方法是事先對已知樣本點進行剪輯�,事先去除對分類作用不大的樣本����。該算法比較適用于樣本容量比較大的類域的自動分類���,而那些樣本容量較小的類域采用這種算法比較容易產生誤分[參考機器學習十大算法]����。
總的來說就是我們已經存在了一個帶標簽的數據庫���,然后輸入沒有標簽的新數據后��,將新數據的每個特征與樣本集中數據對應的特征進行比較�,然后算法提取樣本集中特征最相似(最近鄰)的分類標簽�。一般來說����,只選擇樣本數據庫中前k個最相似的數據��。最后���,選擇k個最相似數據中出現次數最多的分類���。其算法描述如下:
1)計算已知類別數據集中的點與當前點之間的距離�;
2)按照距離遞增次序排序����;
3)選取與當前點距離最小的k個點���;
4)確定前k個點所在類別的出現頻率���;
5)返回前k個點出現頻率最高的類別作為當前點的預測分類���。
二���、Python實現
對于機器學習而已��,Python需要額外安裝三件寶�����,分別是Numpy�����,scipy和Matplotlib����。前兩者用于數值計算���,后者用于畫圖�。安裝很簡單��,直接到各自的官網下載回來安裝即可�����。安裝程序會自動搜索我們的python版本和目錄����,然后安裝到python支持的搜索路徑下����。反正就python和這三個插件都默認安裝就沒問題了�。
另外����,如果我們需要添加我們的腳本目錄進Python的目錄(這樣Python的命令行就可以直接import)�,可以在系統環境變量中添加:PYTHONPATH環境變量���,值為我們的路徑�,例如:E:\Python\Machine Learning in Action
2.1��、kNN基礎實踐
一般實現一個算法后��,我們需要先用一個很小的數據庫來測試它的正確性���,否則一下子給個大數據給它��,它也很難消化��,而且還不利于我們分析代碼的有效性���。
首先�,我們新建一個kNN.py腳本文件���,文件里面包含兩個函數����,一個用來生成小數據庫��,一個實現kNN分類算法��。代碼如下:
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
#########################################
# kNN: k Nearest Neighbors
# Input: newInput: vector to compare to existing dataset (1xN)
# dataSet: size m data set of known vectors (NxM)
# labels: data set labels (1xM vector)
# k: number of neighbors to use for comparison
# Output: the most popular class label
#########################################
from numpy import *
import operator
# create a dataset which contains 4 samples with 2 classes
def createDataSet():
# create a matrix: each row as a sample
group = array([[1.0, 0.9], [1.0, 1.0], [0.1, 0.2], [0.0, 0.1]])
labels = ['A', 'A', 'B', 'B'] # four samples and two classes
return group, labels
# classify using kNN
def kNNClassify(newInput, dataSet, labels, k):
numSamples = dataSet.shape[0] # shape[0] stands for the num of row
## step 1: calculate Euclidean distance
# tile(A, reps): Construct an array by repeating A reps times
# the following copy numSamples rows for dataSet
diff = tile(newInput, (numSamples, 1)) - dataSet # Subtract element-wise
squaredDiff = diff ** 2 # squared for the subtract
squaredDist = sum(squaredDiff, axis = 1) # sum is performed by row
distance = squaredDist ** 0.5
## step 2: sort the distance
# argsort() returns the indices that would sort an array in a ascending order
sortedDistIndices = argsort(distance)
classCount = {} # define a dictionary (can be append element)
for i in xrange(k):
## step 3: choose the min k distance
voteLabel = labels[sortedDistIndices[i]]
## step 4: count the times labels occur
# when the key voteLabel is not in dictionary classCount, get()
# will return 0
classCount[voteLabel] = classCount.get(voteLabel, 0) + 1
## step 5: the max voted class will return
maxCount = 0
for key, value in classCount.items():
if value > maxCount:
maxCount = value
maxIndex = key
return maxIndex
然后我們在命令行中這樣測試即可:
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
import kNN
from numpy import *
dataSet, labels = kNN.createDataSet()
testX = array([1.2, 1.0])
k = 3
outputLabel = kNN.kNNClassify(testX, dataSet, labels, 3)
print "Your input is:", testX, "and classified to class: ", outputLabel
testX = array([0.1, 0.3])
outputLabel = kNN.kNNClassify(testX, dataSet, labels, 3)
print "Your input is:", testX, "and classified to class: ", outputLabel
這時候會輸出:
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
Your input is: [ 1.2 1.0] and classified to class: A
Your input is: [ 0.1 0.3] and classified to class: B
2.2��、kNN進階
這里我們用kNN來分類一個大點的數據庫�����,包括數據維度比較大和樣本數比較多的數據庫�����。這里我們用到一個手寫數字的數據庫����,可以到這里下載����。這個數據庫包括數字0-9的手寫體���。每個數字大約有200個樣本���。每個樣本保持在一個txt文件中�。手寫體圖像本身的大小是32x32的二值圖����,轉換到txt文件保存后����,內容也是32x32個數字����,0或者1��,如下:

數據庫解壓后有兩個目錄:目錄trainingDigits存放的是大約2000個訓練數據��,testDigits存放大約900個測試數據�。
這里我們還是新建一個kNN.py腳本文件�,文件里面包含四個函數�����,一個用來生成將每個樣本的txt文件轉換為對應的一個向量����,一個用來加載整個數據庫�,一個實現kNN分類算法�����。最后就是實現這個加載�,測試的函數����。
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
#########################################
# kNN: k Nearest Neighbors
# Input: inX: vector to compare to existing dataset (1xN)
# dataSet: size m data set of known vectors (NxM)
# labels: data set labels (1xM vector)
# k: number of neighbors to use for comparison
# Output: the most popular class label
#########################################
from numpy import *
import operator
import os
# classify using kNN
def kNNClassify(newInput, dataSet, labels, k):
numSamples = dataSet.shape[0] # shape[0] stands for the num of row
## step 1: calculate Euclidean distance
# tile(A, reps): Construct an array by repeating A reps times
# the following copy numSamples rows for dataSet
diff = tile(newInput, (numSamples, 1)) - dataSet # Subtract element-wise
squaredDiff = diff ** 2 # squared for the subtract
squaredDist = sum(squaredDiff, axis = 1) # sum is performed by row
distance = squaredDist ** 0.5
## step 2: sort the distance
# argsort() returns the indices that would sort an array in a ascending order
sortedDistIndices = argsort(distance)
classCount = {} # define a dictionary (can be append element)
for i in xrange(k):
## step 3: choose the min k distance
voteLabel = labels[sortedDistIndices[i]]
## step 4: count the times labels occur
# when the key voteLabel is not in dictionary classCount, get()
# will return 0
classCount[voteLabel] = classCount.get(voteLabel, 0) + 1
## step 5: the max voted class will return
maxCount = 0
for key, value in classCount.items():
if value > maxCount:
maxCount = value
maxIndex = key
return maxIndex
# convert image to vector
def img2vector(filename):
rows = 32
cols = 32
imgVector = zeros((1, rows * cols))
fileIn = open(filename)
for row in xrange(rows):
lineStr = fileIn.readline()
for col in xrange(cols):
imgVector[0, row * 32 + col] = int(lineStr[col])
return imgVector
# load dataSet
def loadDataSet():
## step 1: Getting training set
print "---Getting training set..."
dataSetDir = 'E:/Python/Machine Learning in Action/'
trainingFileList = os.listdir(dataSetDir + 'trainingDigits') # load the training set
numSamples = len(trainingFileList)
train_x = zeros((numSamples, 1024))
train_y = []
for i in xrange(numSamples):
filename = trainingFileList[i]
# get train_x
train_x[i, :] = img2vector(dataSetDir + 'trainingDigits/%s' % filename)
# get label from file name such as "1_18.txt"
label = int(filename.split('_')[0]) # return 1
train_y.append(label)
## step 2: Getting testing set
print "---Getting testing set..."
testingFileList = os.listdir(dataSetDir + 'testDigits') # load the testing set
numSamples = len(testingFileList)
test_x = zeros((numSamples, 1024))
test_y = []
for i in xrange(numSamples):
filename = testingFileList[i]
# get train_x
test_x[i, :] = img2vector(dataSetDir + 'testDigits/%s' % filename)
# get label from file name such as "1_18.txt"
label = int(filename.split('_')[0]) # return 1
test_y.append(label)
return train_x, train_y, test_x, test_y
# test hand writing class
def testHandWritingClass():
## step 1: load data
print "step 1: load data..."
train_x, train_y, test_x, test_y = loadDataSet()
## step 2: training...
print "step 2: training..."
pass
## step 3: testing
print "step 3: testing..."
numTestSamples = test_x.shape[0]
matchCount = 0
for i in xrange(numTestSamples):
predict = kNNClassify(test_x[i], train_x, train_y, 3)
if predict == test_y[i]:
matchCount += 1
accuracy = float(matchCount) / numTestSamples
## step 4: show the result
print "step 4: show the result..."
print 'The classify accuracy is: %.2f%%' % (accuracy * 100)
測試非常簡單�,只需要在命令行中輸入:
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
import kNN
kNN.testHandWritingClass()
輸出結果如下:
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
step 1: load data... 數據分析師培訓
---Getting training set...
---Getting testing set...
step 2: training...
step 3: testing...
step 4: show the result...
The classify accuracy is: 98.84%
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
