機器學習算法與Python實踐之(二)支持向量機(SVM)初級
一��、引入
支持向量機(SupportVector Machines)�����,這個名字可是響當當的����,在機器學習或者模式識別領域可是無人不知���,無人不曉啊����。八九十年代的時候���,和神經網絡一決雌雄�,獨領風騷�����,并吸引了大批為之狂熱和追隨的粉絲����。雖然幾十年過去了�,但風采不減當年���,在模式識別領域依然占據著大遍江山�����。王位穩固了幾十年��。當然了���,它也繁衍了很多子子孫孫���,出現了很多基因改良的版本����,也發展了不少裙帶關系���。但其中的睿智依然被世人稱道�����,并將千秋萬代���!
好了��,買了那么久廣告���,不知道是不是高估了��。我們還是腳踏實地����,來看看傳說的SVM是個什么東西吧���。我們知道��,分類的目的是學會一個分類函數或分類模型(或者叫做分類器)��,該模型能把數據庫中的數據項映射到給定類別中的某一個�,從而可以用于預測未知類別����。對于用于分類的支持向量機����,它是個二分類的分類模型����。也就是說���,給定一個包含正例和反例(正樣本點和負樣本點)的樣本集合�����,支持向量機的目的是尋找一個超平面來對樣本進行分割�,把樣本中的正例和反例用超平面分開����,但是不是簡單地分看��,其原則是使正例和反例之間的間隔最大���。學習的目標是在特征空間中找到一個分類超平面wx+b=0�����,分類面由法向量w和截距b決定�����。分類超平面將特征空間劃分兩部分�����,一部分是正類�����,一部分是負類���。法向量指向的一側是正類�,另一側為負類���。
用一個二維空間里僅有兩類樣本的分類問題來舉個小例子���。假設我們給定了下圖左圖所示的兩類點Class1和Class2(也就是正樣本集和負樣本集)��。我們的任務是要找到一個線��,把他們劃分開�����。你會告訴我�,那簡單�����,揮筆一畫�,洋洋灑灑五顏六色的線就出來了����,然后很得意的和我說���,看看吧���,下面右圖���,都是你要的答案��,如果你還想要����,我還可以給你畫出無數條�。對��,沒錯���,的確可以畫出無數條��。那哪條最好呢��?你會問我�,怎么樣衡量“好”�����?假設Class1和Class2分別是兩條村子的人��,他們因為兩條村子之間的地盤分割的事鬧僵了����,叫你去說個理�,到底怎么劃分才是最公平的����。這里的“好”���,可以理解為對Class1和Class2都是公平的���。然后你二話不說��,指著黑色那條線�,說“就它了��!正常人都知道�����!在兩條村子最中間畫條線很明顯對他們就是公平的��,誰也別想多�����,誰也沒拿少”�����。這個例子可能不太恰當�,但道理還是一樣的���。對于分類來說�,我們需要確定一個分類的線��,如果新的一個樣本到來��,如果落在線的左邊�����,那么這個樣本就歸為class1類����,如果落在線的右邊�,就歸為class2這一類��。那哪條線才是最好的呢��?我們仍然認為是中間的那條���,因為這樣�����,對新的樣本的劃分結果我們才認為最可信�,那這里的“好”就是可信了��。另外�,在二維空間���,分類的就是線����,如果是三維的�,分類的就是面了��,更高維�,也有個霸氣的名字叫超平面�。因為它霸氣��,所以一般將任何維的分類邊界都統稱為超平面����。
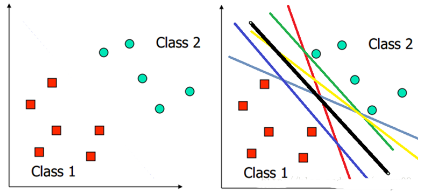
好了��。對于人來說�����,我們可以輕易的找到這條線或者超平面(當然了�����,那是因為你可以看到樣本具體的分布是怎樣的�����,如果樣本的維度大于三維的話�,我們就沒辦法把這些樣本像上面的圖一樣畫出來了����,這時候就看不到了�����,這時候靠人的雙眼也無能為力了���?!叭绻夷芸吹靡?��,生命也許完全不同���,可能我想要的�����,我喜歡的我愛的�����,都不一樣……”)����,但計算機怎么知道怎么找到這條線呢�����?我們怎么把我們的找這條線的方法告訴他���,讓他按照我們的方法來找到這條線呢���?呃�����,我們要建模?��。�����?!把我們的意識“強加”給計算機的某個數學模型���,讓他去求解這個模型�����,得到某個解�����,這個解就是我們的這條線�����,那這樣目的就達到了����。那下面就得開始建模之旅了���。
二�����、線性可分SVM與硬間隔最大化
其實上面這種分類思想就是SVM的思想����?�?梢员磉_為:SVM試圖尋找一個超平面來對樣本進行分割���,把樣本中的正例和反例用超平面分開�,但是不是很敷衍地簡單的分開��,而是盡最大的努力使正例和反例之間的間隔margin最大�����。這樣它的分類結果才更加可信����,而且對于未知的新樣本才有很好的分類預測能力(機器學習美其名曰泛化能力)�。
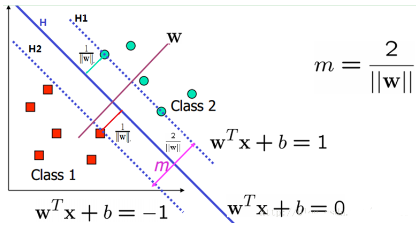
我們的目標是尋找一個超平面����,使得離超平面比較近的點能有更大的間距���。也就是我們不考慮所有的點都必須遠離超平面�,我們關心求得的超平面能夠讓所有點中離它最近的點具有最大間距�����。
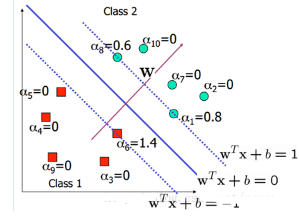
我們先用數學公式來描述下����。假設我們有N個訓練樣本{(x1, y1),(x2, y2), …, (xN, yN)}�,x是d維向量�,而yi?{+1, -1}是樣本的標簽����,分別代表兩個不同的類�����。這里我們需要用這些樣本去訓練學習一個線性分類器(超平面):f(x)=sgn(wTx + b)��,也就是wTx + b大于0的時候��,輸出+1��,小于0的時候�����,輸出-1���。sgn()表示取符號��。而g(x) =wTx + b=0就是我們要尋找的分類超平面���,如上圖所示�����。剛才說我們要怎么做了��?我們需要這個超平面最大的分隔這兩類�。也就是這個分類面到這兩個類的最近的那個樣本的距離相同���,而且最大��。為了更好的說明����,我們在上圖中找到兩個和這個超平面平行和距離相等的超平面:H1: y = wTx + b=+1 和 H2: y = wTx + b=-1����。
好了�����,這時候我們就需要兩個條件:(1)沒有任何樣本在這兩個平面之間�;(2)這兩個平面的距離需要最大�����。(對任何的H1和H2��,我們都可以歸一化系數向量w��,這樣就可以得到H1和H2表達式的右邊分別是+1和-1了)����。先來看條件(2)��。我們需要最大化這個距離�,所以就存在一些樣本處于這兩條線上�,他們叫支持向量(后面會說到他們的重要性)����。那么它的距離是什么呢��?我們初中就學過����,兩條平行線的距離的求法��,例如ax+by=c1和ax+by=c2�,那他們的距離是|c2-c1|/sqrt(x2+y2)(sqrt()表示開根號)�。注意的是����,這里的x和y都表示二維坐標���。而用w來表示就是H1:w1x1+w2x2=+1和H2:w1x1+w2x2=-1����,那H1和H2的距離就是|1+1|/ sqrt(w12+w12)=2/||w||��。也就是w的模的倒數的兩倍�����。也就是說�����,我們需要最大化margin=2/||w||�,為了最大化這個距離�����,我們應該最小化||w||����,看起來好簡單哦�����。同時我們還需要滿足條件(2)����,也就是同時要滿足沒有數據點分布在H1和H2之間:
也就是���,對于任何一個正樣本yi=+1��,它都要處于H1的右邊����,也就是要保證:y= wTx + b>=+1��。對于任何一個負樣本yi=-1�,它都要處于H2的左邊�����,也就是要保證:y = wTx + b<=-1���。這兩個約束���,其實可以合并成同一個式子:yi (wTxi + b)>=1���。
所以我們的問題就變成:
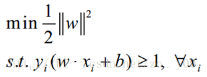
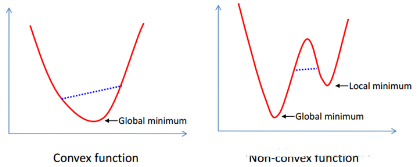
這是個凸二次規劃問題�����。什么叫凸�����?凸集是指有這么一個點的集合��,其中任取兩個點連一條直線��,這條線上的點仍然在這個集合內部�����,因此說“凸”是很形象的���。例如下圖���,對于凸函數(在數學表示上�,滿足約束條件是仿射函數����,也就是線性的Ax+b的形式)來說����,局部最優就是全局最優��,但對非凸函數來說就不是了�����。二次表示目標函數是自變量的二次函數���。
好了�,既然是凸二次規劃問題�����,就可以通過一些現成的 QP (Quadratic Programming) 的優化工具來得到最優解��。所以����,我們的問題到此為止就算全部解決了����。雖然這個問題確實是一個標準的 QP 問題�,但是它也有它的特殊結構�,通過 Lagrange Duality 變換到對偶變量 (dual variable) 的優化問題之后���,可以找到一種更加有效的方法來進行求解�����,而且通常情況下這種方法比直接使用通用的 QP 優化包進行優化要高效得多��。也就說�����,除了用解決QP問題的常規方法之外����,還可以應用拉格朗日對偶性��,通過求解對偶問題得到最優解�,這就是線性可分條件下支持向量機的對偶算法���,這樣做的優點在于:一是對偶問題往往更容易求解�����;二者可以自然的引入核函數���,進而推廣到非線性分類問題�。那什么是對偶問題���?
三�、Dual優化問題
3.1����、對偶問題
在約束最優化問題中��,常常利用拉格朗日對偶性將原始問題轉換為對偶問題�,通過求解對偶問題而得到原始問題的解��。至于這其中的原理和推導參考文獻[3]講得非常好�。大家可以參考下����。這里只將對偶問題是怎么操作的�。假設我們的優化問題是:
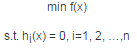
這是個帶等式約束的優化問題�。我們引入拉格朗日乘子����,得到拉格朗日函數為:
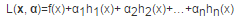
然后我們將拉格朗日函數對x求極值�,也就是對x求導���,導數為0�����,就可以得到α關于x的函數��,然后再代入拉格朗日函數就變成:
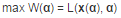
這時候����,帶等式約束的優化問題就變成只有一個變量α(多個約束條件就是向量)的優化問題����,這時候的求解就很簡單了�。同樣是求導另其等于0��,解出α即可�����。需要注意的是��,我們把原始的問題叫做primal problem���,轉換后的形式叫做dual problem����。需要注意的是����,原始問題是最小化�����,轉化為對偶問題后就變成了求最大值了�。對于不等式約束�����,其實是同樣的操作�����。簡單地來說�,通過給每一個約束條件加上一個 Lagrange multiplier(拉格朗日乘子)��,我們可以將約束條件融和到目標函數里去�����,這樣求解優化問題就會更加容易�。(這里其實涉及到很多蠻有趣的東西的��,大家可以參考更多的博文)
3.2��、SVM優化的對偶問題
對于SVM����,前面提到����,其primal problem是以下形式:
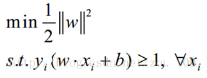
同樣的方法引入拉格朗日乘子��,我們就可以得到以下拉格朗日函數:
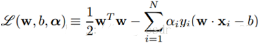
然后對L(w, b, α)分別求w和b的極值�����。也就是L(w, b,α)對w和b的梯度為0:?L/?w=0和?L/?b=0����,還需要滿足α>=0���。求解這里導數為0的式子可以得到:
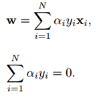
然后再代入拉格朗日函數后����,就變成:
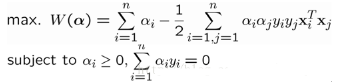
這個就是dual problem(如果我們知道α����,我們就知道了w���。反過來�����,如果我們知道w�,也可以知道α)����。這時候我們就變成了求對α的極大��,即是關于對偶變量α的優化問題(沒有了變量w�,b����,只有α)�。當求解得到最優的α*后��,就可以同樣代入到上面的公式���,導出w*和b*了��,最終得出分離超平面和分類決策函數�。也就是訓練好了SVM�����。那來一個新的樣本x后����,就可以這樣分類了:
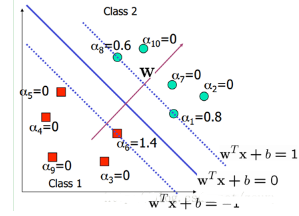
在這里��,其實很多的αi都是0��,也就是說w只是一些少量樣本的線性加權值���。這種“稀疏”的表示實際上看成是KNN的數據壓縮的版本��。也就是說�����,以后新來的要分類的樣本首先根據w和b做一次線性運算���,然后看求的結果是大于0還是小于0來判斷正例還是負例?�,F在有了αi���,我們不需要求出w����,只需將新來的樣本和訓練數據中的所有樣本做內積和即可����。那有人會說���,與前面所有的樣本都做運算是不是太耗時了�����?其實不然���,我們從KKT條件中得到����,只有支持向量的αi不為0�,其他情況αi都是0�����。因此��,我們只需求新來的樣本和支持向量的內積�,然后運算即可���。這種寫法為下面要提到的核函數(kernel)做了很好的鋪墊�。如下圖所示:
四����、松弛向量與軟間隔最大化
我們之前討論的情況都是建立在樣本的分布比較優雅和線性可分的假設上���,在這種情況下可以找到近乎完美的超平面對兩類樣本進行分離�����。但如果遇到下面這兩種情況呢���?左圖����,負類的一個樣本點A不太合群�,跑到正類這邊了����,這時候如果按上面的確定分類面的方法�����,那么就會得到左圖中紅色這條分類邊界��,嗯�����,看起來不太爽��,好像全世界都在將就A一樣���。還有就是遇到右圖的這種情況���。正類的一個點和負類的一個點都跑到了別人家門口����,這時候就找不到一條直線來將他們分開了���,那這時候怎么辦呢��?我們真的要對這些零丁的不太聽話的離群點屈服和將就嗎���?就因為他們的不完美改變我們原來完美的分界面會不會得不償失呢��?但又不得不考慮他們���,那怎樣才能折中呢�?
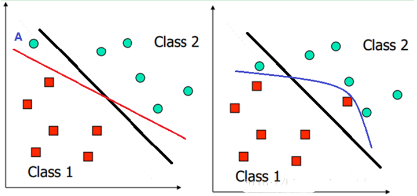
對于上面說的這種偏離正常位置很遠的數據點��,我們稱之為 outlier��,它有可能是采集訓練樣本的時候的噪聲���,也有可能是某個標數據的大叔打瞌睡標錯了��,把正樣本標成負樣本了���。那一般來說���,如果我們直接忽略它���,原來的分隔超平面還是挺好的���,但是由于這個 outlier 的出現��,導致分隔超平面不得不被擠歪了�����,同時 margin 也相應變小了��。當然����,更嚴重的情況是���,如果出現右圖的這種outlier�,我們將無法構造出能將數據線性分開的超平面來����。
為了處理這種情況��,我們允許數據點在一定程度上偏離超平面����。也就是允許一些點跑到H1和H2之間��,也就是他們到分類面的間隔會小于1�����。如下圖:
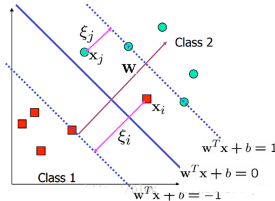
具體來說��,原來的約束條件就變為:
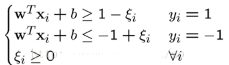
這時候���,我們在目標函數里面增加一個懲罰項����,新的模型就變成(也稱軟間隔):
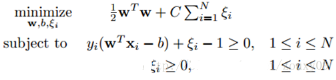
引入非負參數ξi后(稱為松弛變量)��,就允許某些樣本點的函數間隔小于1�,即在最大間隔區間里面�����,或者函數間隔是負數����,即樣本點在對方的區域中�。而放松限制條件后�����,我們需要重新調整目標函數�����,以對離群點進行處罰����,目標函數后面加上的第二項就表示離群點越多���,目標函數值越大����,而我們要求的是盡可能小的目標函數值�����。這里的C是離群點的權重��,C越大表明離群點對目標函數影響越大�����,也就是越不希望看到離群點�。這時候����,間隔也會很小��。我們看到�,目標函數控制了離群點的數目和程度�����,使大部分樣本點仍然遵守限制條件���。數據分析師培訓
這時候�����,經過同樣的推導過程����,我們的對偶優化問題變成:
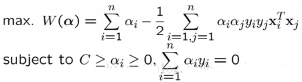
此時���,我們發現沒有了參數ξi�����,與之前模型唯一不同在于αi又多了αi<=C的限制條件���。需要提醒的是�,b的求值公式也發生了改變��,改變結果在SMO算法里面介紹���。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
