R語言之文本挖掘--分詞
當前對文本挖掘的需求越來越多���,而基于文本挖掘又可以實現輿情監控�、文本分類���、關聯分析和趨勢預測等���。
本文主要使用李艦發布的中文分詞包Rwordseg���。該包引用了@ansj開發的ansj中文分詞工具���,基于中科院的ictclas中文分詞算法���,無論是分詞準確度�、自定義詞典的方便程度還是運行的效率都大大地超過了rmmseg4j�。該包使用rJava調用Java分詞工具Ansj�,因此需要進行rJava的設置才可以使用�。
文中使用到Rwordseg包和tmcn包�,這兩個包目前不在R的鏡像中����,可以通過如下兩種方式獲得這兩個包�。
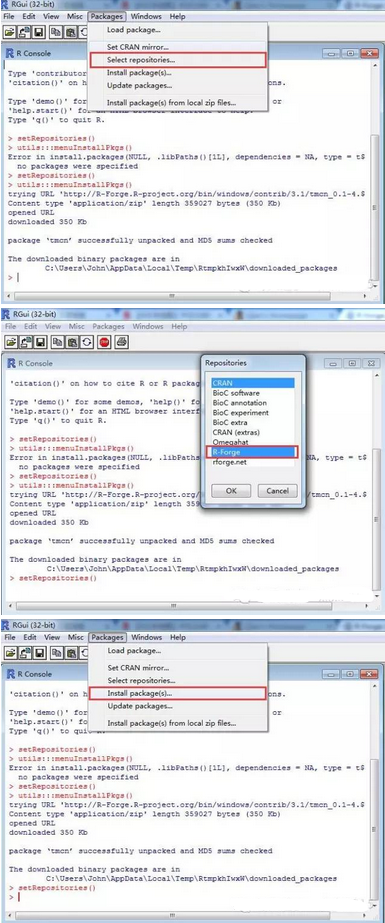
1�、通過R語言本身獲得�,詳細步驟見下圖:
2����、直接到R-Forge官網下載并安裝�����,下載地址如下:
https://r-forge.r-project.org/R/?group_id=1054
https://r-forge.r-project.org/R/?group_id=1571
應用:
本文分析的對象為一篇新聞����,來源于環球網的《習近平出席中美企業家座談會》這篇文章���,看看習大大這次訪美都有哪些動向�?
本文主要對這篇文章做如下兩個工作:分詞和繪制文字云�。
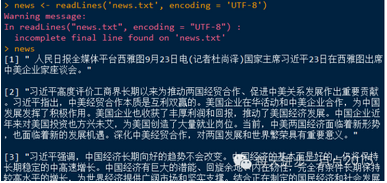
#讀取數據
news <- readLines('news.txt', encoding = 'UTF-8')
由于Rwordseg包中的segmentCN函數對某些詞無法準確分詞��,需要自定義字典��、指定人名識別及指定停止詞���。
#首先將臺灣大學定義的字典導入到系統中��,該字典中含有正面及負面的簡體詞和繁體詞共22173個����。
data(NTUSD)
positive_simple <- NTUSD[[1]]
negtive_simple <- NTUSD[[2]]
positive_tradition <- NTUSD[[3]]
negtive_tradition <- NTUSD[[4]]
insertWords(positive_simple)
insertWords(negtive_simple)
insertWords(positive_tradition)
insertWords(negtive_tradition)
#其次將自定義的詞導入系統
dir <- c('中美','兩國','阿里巴巴','改革開放','騰訊','微軟',
'雙匯','亞馬遜','星巴克','企業家','發展中','中國夢')
insertWords(dir)
#再者還需要指定人名識別
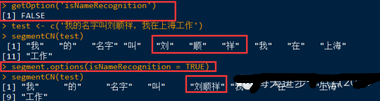
發現默認情況下�����,segmentCN函數并沒有識別人名���。
將人名識別設為TURE后�,發現能夠將名字準確分割出來�。
#最后為分詞函數segmentCN指定停止詞�,這樣就不會把這些詞識別為有效詞
stopwords <- c('大','上','高','好','中','新','更','夢')
stopword <- stopwordsCN(stopwords = stopwords, useStopDic = TRUE)
當然這些準備工作是在探索文本內容的基礎上完成的�����,這里只是想說明一下本文的思路���。
使用segmentCN函數看一下分詞效果:

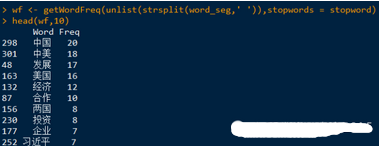
詞頻分析
繪制文字云
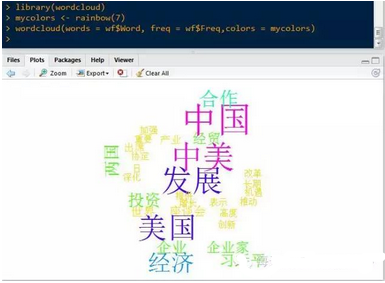
從圖中發現�����,本次習總書記訪問美國��,仍然強調的是中美之間的經濟發展問題�。
由于工作需要�����,自己剛開始研究文本挖掘���,本文只是做了個文本的分詞����,關于文本挖掘還有許多知識需要學習�����,例如文本的聚類�、關聯規則�、預測等��。接下來的日子里將和文本挖掘扯上很大的關系啦����。�����。���。����。
最后總結一下本文所涉及到的R包和函數:
tm包
insertWords()
tmcn包
getWordFreq()
Rwordseg包
getOption()
segment.options()
stopwordsCN()
segmentCN()
wordcloud包
wordcloud()
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
