數據挖掘算法(logistic回歸����,隨機森林����,GBDT和xgboost)
面網易數據挖掘工程師崗位�,第一次面數據挖掘的崗位�,只想著能夠去多準備一些���,體驗面這個崗位的感覺��,雖然最好心有不甘告終�����,不過繼續加油��。
不過總的來看��,面試前有準備永遠比你沒有準備要強好幾倍�����。
因為面試過程看重的不僅是你的實習經歷多久怎樣����,更多的是看重你對基礎知識的掌握(即學習能力和邏輯)���,實際項目中解決問題的能力(做了什么貢獻)�。
先提一下奧卡姆剃刀:給定兩個具有相同泛化誤差的模型�����,較簡單的模型比較復雜的模型更可取�����。以免模型過于復雜���,出現過擬合的問題�����。
如果你想面數據挖掘崗必須先了解下面這部分的基本算法理論:
我們知道�����,在做數學題的時候��,解未知數的方法���,是給定自變量和函數��,通過函數處理自變量���,以獲得解��。而機器學習就相當于����,給定自變量和函數的解�,求函數��。
類似于:這樣:function(x)=y
機器學習就是樣本中有大量的x(特征量)和y(目標變量)然后求這個function�����。
求函數的方法�,基于理論上來說�,大部分函數都能找到一個近似的泰勒展開式����。而機器學習����,就是用數據去擬合這個所謂的“近似的泰勒展開式”�。
實際面試時很看重和考察你的理論基礎����,所以一定一定要重視各個算法推導過程中的細節問題����。這里主要介紹:logistic回歸���,隨機森林����,GBDT和Adaboost
邏輯回歸從統計學的角度看屬于非線性回歸中的一種����,它實際上是一種分類方法��,主要用于兩分類問題
Regression問題的常規步驟為:
尋找h函數(即假設估計的函數)��;
構造J函數(損失函數)��;
想辦法使得J函數最小并求得回歸參數(θ)�����;
數據擬合問題
1)利用了Logistic函數(或稱為Sigmoid函數)�,函數形式為最常見的
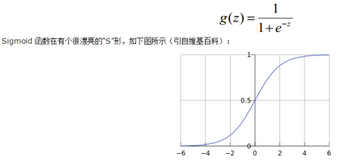
1.png
2)代價函數J
下面的代價函數J之所有前面加上1/m是為了后面”梯度下降求參數θ時更方便“��,也即這里不加1/m也可以����。

2.png
3.png

4.png

5.png
3)使得J函數最小并求得回歸參數(θ)
如何調整θ以使得J(θ)取得最小值有很多方法���,比如最小二乘法�����,梯度下降也是一種����,這里介紹一下梯度下降����。
梯度下降是最基礎的一個優化算法�,學習因子就是梯度下降里的學習率��,一個參數�。
梯度方向表示了函數增長速度最快的方向���,那么和它相反的方向就是函數減少速度最快的方向了���。對于機器學習模型優化的問題��,當我們需要求解最小值的時候�,朝著梯度下降的方向走��,就能找到最優值了�。
學習因子即步長α的選擇對梯度下降算法來說很重要�,α過小會導致收斂太慢���;若α太大�����,可能跳過最優���,從而找不到最優解����。
1)當梯度下降到一定數值后��,每次迭代的變化很小�,這時可以設定一個閾值�,**只要變化小于該閾值���,就停止迭代��,而得到的結果也近似于最優解��。**
2)若損失函數的值不斷變大��,則有可能是步長速率a太大�����,導致算法不收斂��,這時可適當調整a值
對于樣本數量額非常之多的情況��,普通的**批量梯度下降**算法(Batch gradient descent )會非常耗時��,靠近極小值時收斂速度減慢�,因為每次迭代都要便利所有樣本���,這時可以選擇**隨機梯度下降算法**(Stochastic gradient descent)梯度下降**需要把m個樣本全部帶入計算**����,迭代一次計算量為m\\*n^2���;隨機梯度下降每次只使用一個樣本��,迭代一次計算量為n^2�����,當m很大的時候����,隨機梯度下降迭代一次的速度要遠高于梯度下降���,雖然不是每次迭代得到的損失函數都向著全局最優方向���,** 但是大的整體的方向是向全局最優解的���,最終的結果往往是在全局最優解附近����。**

6.png
4)數據的擬合問題
第一種是欠擬合�,通常是因為特征量選少了���。
第二種是我們想要的���。
第三個是過擬合�����,通常是因為特征量選多了��。
欠擬合的解決方法是增加特征量����。
過擬合的解決方法是減少特征量或者正則化���。
但是一般情況下我們又不能確定哪些特征量該去掉�,所以我們就選擇正則化的方式解決過擬合�����。

7.png
決策樹這種算法有著很多良好的特性�,比如說訓練時間復雜度較低����,預測的過程比較快速���,模型容易展示����。單決策樹又有一些不好的地方��,比如說容易over-fitting
這里首先介紹如何構造決策樹:
(1)如何分割某一結點���,方法有很多���,分別針對二元屬性����、序數屬性����、連續屬性等進行劃分��。
(2)在有多個特征時�,如何確定最佳的分割特征��。
這里就涉及到純度的概念�,若分割后的子結點都更偏向于一個類���,那么純度越高�。
但實際中我們通常對不純度進行度量�,即不純度越小����,則認為該特征的區分度越高��。
不純度的度量方式有三種:

8.png
具體的計算方法如下:

9.png
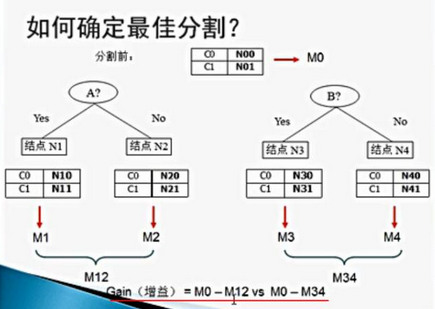
10.png
上圖10中得到多個子結點M1����,M2的GINI或者熵后��,一般通過加權平均的方法求M12;
那么增益就可以用M0-M12來表示
在決策樹算法中��,通過比較劃分前后的不純度值��,來確定如何分裂�。ID3使用信息增益作為不純度����,C4.5使用信息增益比作為不純度�����,CART使用基尼指數作為不純度���。
信息增益為:父結點與所有子結點不純程度的差值���,差越大��,則增益越大�,表示特征的效果越好���。
有時候并不是分割的越多越好�����,如果某個特征產生了大量的劃分�����,它的劃分信息將會很大��,此時采用信息增益率
以ID3為例���,使用訓練樣本建立決策樹時�����,在每一個內部節點依據信息論來評估選擇哪一個屬性作為分割
的依據�����。對于過擬合的問題��,一般要對決策樹進行剪枝���,剪枝有兩種方法:先剪枝�,后剪枝����。
先剪枝說白了就是提前結束決策樹的增長�����,跟上述決策樹停止生長的方法一樣�。
后剪枝是指在決策樹生長完成之后再進行剪枝的過程���。
(3)何時停止劃分���。

11.png
隨機森林是一個包含多個決策樹的分類器�����,構建過程如下:
1)決策樹相當于一個大師����,通過自己在數據集中學到的知識對于新的數據進行分類����。但是俗話說得好��,一個諸葛亮����,玩不過三個臭皮匠����。隨機森林就是希望構建多個臭皮匠���,希望最終的分類效果能夠超過單個大師的一種算法���。
2)那隨機森林具體如何構建呢�����?有兩個方面:數據的隨機性選取��,以及待選特征的隨機選取�。
數據的隨機選?。?br />
第一�,從原始的數據集中采取有放回的抽樣����,構造子數據集����,子數據集的數據量是和原始數據集相同的�。不同子數據集的元素可以重復�,同一個子數據集中的元素也可以重復�����。
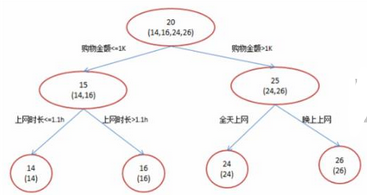
第二�����,利用子數據集來構建子決策樹��,將這個數據放到每個子決策樹中��,每個子決策樹輸出一個結果���。最后��,如果有了新的數據需要通過隨機森林得到分類結果�����,就可以通過對子決策樹的判斷結果的投票���,得到隨機森林的輸出結果了�。如下圖��,假設隨機森林中有3棵子決策樹�,2棵子樹的分類結果是A類��,1棵子樹的分類結果是B類���,那么隨機森林的分類結果就是A類�。
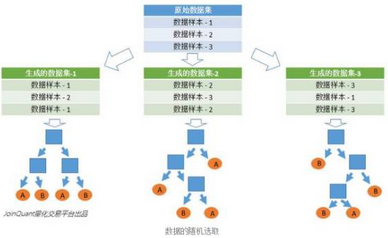
12.png
待選特征的隨機選?�。?br />
與數據集的隨機選取類似��,隨機森林中的子樹的每一個分裂過程并未用到所有的待選特征���,而是從所有的待選特征中隨機選取一定的特征����,之后再在隨機選取的特征中選取最優的特征����。這樣能夠使得隨機森林中的決策樹都能夠彼此不同����,提升系統的多樣性�,從而提升分類性能����。
此外����,以決策樹為基函數的提升方法稱為提升樹(boosting tree)����,包括GBDT,xgboost,adaboost��,這里只主要介紹GBDT和xgboost�����。
先說說bootstrap, bagging���,boosting 的含義��。
Bootstrap是一種有放回的抽樣方法思想�。
該思想的應用有兩方面:bagging和boosting
雖然都是有放回的抽樣����,但二者的區別在于:Bagging采用有放回的均勻取樣�,而Boosting根據錯誤率來取樣(Boosting初始化時對每一個訓練例賦相等的權重1/n�,然后用該學算法對訓練集訓練t輪�,每次訓練后����,對訓練失敗的訓練例賦以較大的權重)��,因此Boosting的分類精度要優于Bagging����。Bagging的訓練集的選擇是隨機的��,各輪訓練集之間相互獨立����,而Boostlng的各輪訓練集的選擇與前面各輪的學習結果有關����。
4.GBDT(Gradient Boost Decision Tree 梯度提升決策樹)
GBDT是以決策樹(CART)為基學習器的GB算法��,是迭代樹���,而不是分類樹����。
Boost是"提升"的意思���,一般Boosting算法都是一個迭代的過程����,每一次新的訓練都是為了改進上一次的結果����。
GBDT的核心就在于:每一棵樹學的是之前所有樹結論和的殘差�,這個殘差就是一個加預測值后能得真實值的累加量���。比如A的真實年齡是18歲����,但第一棵樹的預測年齡是12歲��,差了6歲�����,即殘差為6歲�。那么在第二棵樹里我們把A的年齡設為6歲去學習�,如果第二棵樹真的能把A分到6歲的葉子節點��,那累加兩棵樹的結論就是A的真實年齡�����;如果第二棵樹的結論是5歲�����,則A仍然存在1歲的殘差�,第三棵樹里A的年齡就變成1歲��,繼續學習����。
13.png

14.png
5.xgboost
xgboos也是以(CART)為基學習器的GB算法**�����,但是擴展和改進了GDBT���。相比GBDT的優點有:
(1)xgboost在代價函數里自帶加入了正則項���,用于控制模型的復雜度�����。
(2)xgboost在進行節點的分裂時����,支持各個特征多線程進行增益計算��,因此算法更快�����,準確率也相對高一些�。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
