數據挖掘案例—藥物選擇決策支持
針對病人的病情和體質情況��,醫生往往需要采用不同的用藥����。本案例通過數據挖掘���,對醫院積累的歷史數據進行分析��,確定病人選擇何種藥物對治療疾病最為有效��,并開發了相應的藥物選擇決策支持系統的應用系統
【案例名稱】藥物選擇決策支持
【案例類型】數據挖掘
【所屬行業】醫藥衛生
【案例版本】1.0
【完成日期】2003年7月2日
【應用軟件】Clementine 7.2英文版
【遵循標準】CRISP-DM
【案例數據來源】Clementine 7.2 Demo自帶數據
【案例應用模型】神經網絡���、C5.0����、Logistic回歸
【案例用途】通過案例實現以下目的:
1�����、 CRISP-DM的標準流程及在解決具體業務問題過程中的應用;
2�����、 理解如何提高數據挖掘模型的效果;
3�����、 理解結果發布的幾種方式���。
【案例簡要描述】
針對病人的病情和體質情況��,醫生往往需要采用不同的用藥�。本案例通過數據挖掘�,對醫院積累的歷史數據進行分析��,確定病人選擇何種藥物對治療疾病最為有效�。并開發了相應的藥物選擇決策支持系統的應用系統�����。
案例正文
【背景介紹】
XX病是一種常見的疾病���,目前有5種藥物可以對其治療�����,分別是——A��、B����、C�����、X���、Y���。不同的藥物對病人有不同的療效���。歷史上�����,醫院往往根據醫生的經驗去判斷針對特定的病人應該選擇何種藥物���。但是由于新醫生的加入��,這種僅僅靠經驗判斷的做法造成了很多誤診�。
該醫院有比較完善的病例留存�,為了改變以上局面�,也為了更好的利用歷史數據和專家經驗���,該醫院決定通過數據挖掘技術對歷史數據進行分析研究����,并期望能夠建立一套有效的藥物選擇決策支持系統��。
【數據說明】
目前有歷史病例數據1200條�,咨詢專家意見�����,我們提取了其中影響選擇藥物的若干個變量記入數據庫����,它們是年齡��、性別���、血壓��、膽固醇含量��、鈉含量�����、鉀含量���,最后一個變量是我們需要確定的選擇藥物����,數據存貯在Microsoft Access數據庫中�。
【數據挖掘過程】
1���、 商業理解
在這個階段我們主要需要描述清楚業務問題����,并對我們手頭擁有的資源有一個非常清晰的認識�。在這個案例中�����,我們需要根據病人的個人情況和身體特征來確定何種藥物對它最為合適����。由于問題比較簡單����,我們的商業理解也比較簡單���。
2��、 數據理解
數據理解階段用來完成對數據質量���、數據之間的基本關系進行探索性分析等項工作���。在這個階段��,我們對歷史數據中的1200條數據進行圖形觀察�,初步觀察病人的情況和身體特征是否與選擇藥物關系明顯����。數據流圖見圖1��。
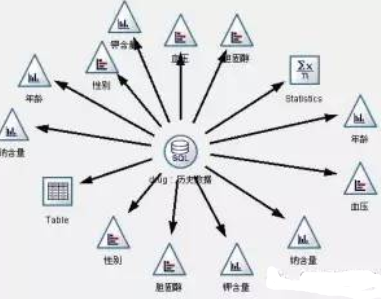
圖1:數據理解
下面是產生的一些典型圖形�����,圖形解釋略�����。

圖2:對數據的初步探索性分析
3�、 數據準備
數據準備主要完成對不同的數據源的整合����,并且對數據進行適當的變換�,使之適合數據挖掘的需要����,對于特定的模型����,需要把原始數據集合拆分成訓練數據集和檢驗數據集也在這個步驟中完成����。
對于本案例來說�,由于數據源只有一個���,并且數據格式也相對單一簡單����,我們在數據準備中主要完成對原始數據集的拆分����,從而用訓練數據集建立模型����,用檢驗數據集對模型的效果進行評估�。
在Clementine中����,對數據集的拆分�,是通過引入一個中間變量來完成的�。在本案例中��,我們把全部1200條數據中的2/3左右(800左右)作為訓練數據集�����,把1/3左右(400左右)作為檢驗數據集�����。我們引入了一個二分變量——拆分變量�,這個二分變量對應1200條原始數據有2/3左右為“真”(T)��,1/3左右為“假”(F)����。我們挑出那些拆分變量值取“真”(T)的記錄作為訓練數據集���,那些拆分變量值取“假”(F)的記錄作為檢驗數據集�����。實現該過程的數據流見圖3��。
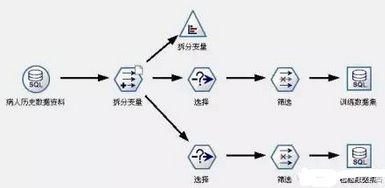
圖3:數據準備
4����、 模型建立和評估
在模型建立階段��,我們將逐步建立和調整模型�,并對如何提高模型的預測效果進行嘗試����。
(1)
建立最簡單的模型��。對于訓練數據集��,我們首先把病人的年齡����、性別�����、血壓���、膽固醇含量�����、鈉含量��、鉀含量等不經過任何處理���,全部作為預測選擇藥物的輸入變量��,而把選擇藥物作為待預測變量(輸出變量)���。數據流圖見圖4���,我們建立了神經網絡�����、C5.0和Logistic回歸三個模型����。
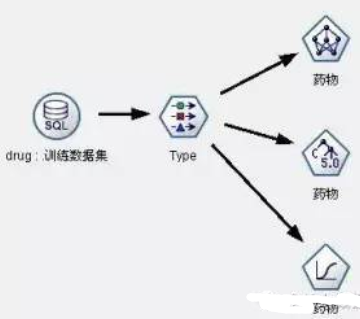
圖4:藥物選擇決策支持模型1
接下來我們用檢驗數據集對模型進行檢驗�����,數據流圖見圖5����。模型檢驗結果見圖6��。從檢驗結果我們可以看出�����,Logistic模型的評估效果最好���,達到了96.21%�����。
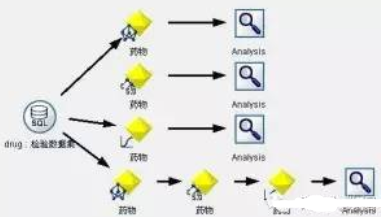
圖5:藥物選擇決策支持模型1檢驗
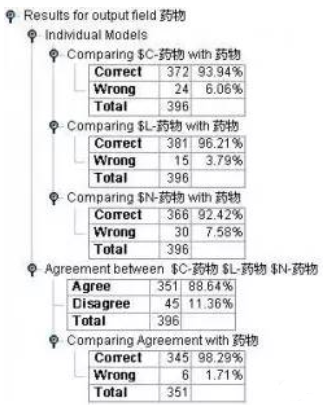
圖6:藥物選擇決策支持模型1檢驗結果
討論——如何提高模型的效果:從模型檢驗中我們可以看出��,三個模型中可能有不一致的情況�,這就使得我們有一種思路�,即我們在發布模型的時候���,可以考慮把那些三個模型預測一致的才作為預測��,而把三者預測不一致的作為待判記錄隨后進行深入的分析�,這樣我們就使得模型的精度提高到了98.29%���,但是作為犧牲�����,我們也會約有12%左右的病人是無法判斷的����,需要我們對記錄做進一步的研究���。
(2)
為了更好的建立和調整模型���,我們對業務進行深入了解����,引入醫生的業務經驗��。根據醫生對醫學理論的討論和過去實踐經驗的積累�,他們認為人體中的鈉含量和鉀含量對病人選擇何種藥物的作用并不是特別明顯��,但是他們的比例卻是影響選擇何種藥物的一個關鍵因素�,所以在我們下面建立的模型中����,我們生成新變量——鈉鉀比例����,而剔除鈉含量和鉀含量兩個變量�。數據流圖見圖7���,模型我們仍舊采用神經網絡�����,C5.0和Logistic回歸三種模型����。
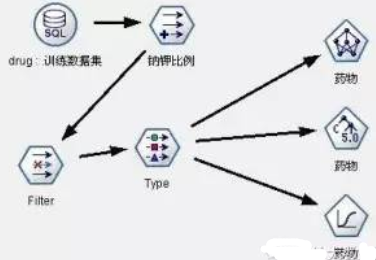
圖7:藥物選擇決策支持模型2
類似(1)��,我們對模型效果進行檢驗���,檢驗數據流和檢驗結果分別如圖8和圖9所示�����。
圖8:藥物選擇決策支持模型2檢驗
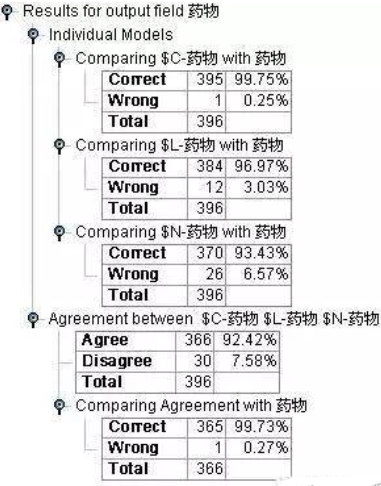
圖9:藥物選擇決策支持模型2檢驗結果
從結果中����,我們可以看出����,隨著我們業務經驗的引入����,我們的模型效果有了顯著的提高�����,并且我們選擇模型也發生了變化����。精度由原來的Logistic回歸最優96.21%提高到了C5.0最優99.75%�����。
5��、 模型發布
模型建立是為了應用���,我們前面的全部工作都在于我們建立的模型能夠被最終的業務人員所使用���,假設我們由以下10個病人的資料數據����,需要根據他們的情況判斷使用什么藥物最好�。
表1:病人資料

該病人資料也被我們存放在Access數據庫中���。我們可以考慮以下三種方式對我們的模型進行發布供業務人員(醫生)使用����。
(1) 直接寫報告的方式�����,通過HTML展示�。數據流圖10����,結果展示實際效果如圖11���。
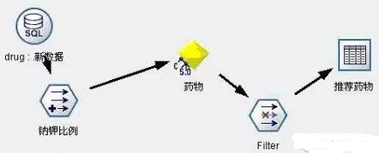
圖10:模型發布數據流1
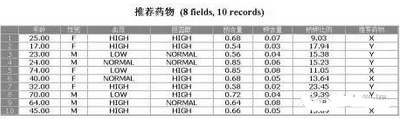
圖11:報告方式發布結果示例
(2) 把選擇藥物直接寫回數據庫�����。數據流如圖12�����,結果大致情形如圖13����。

圖12:模型發布數據流2

圖13:模型發布—把結果寫回數據庫
(3) 通過Clementine Solution Publisher結合Visual C++開發應用系統界面�,業務人員(醫生)可以直接輸入病人資料�,實時的得到藥物推薦���。發布數據流見圖14��,系統界面如圖15�����。
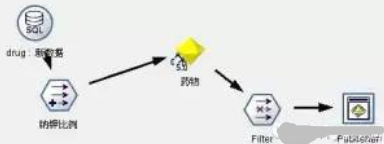
圖14:模型發布數據流3
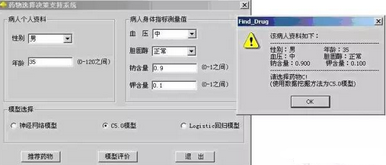
圖15:模型發布——開發應用系統
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
