大數據分析之聚類算法
1. 什么是聚類算法
所謂聚類��,就是比如給定一些元素或者對象���,分散存儲在數據庫中�,然后根據我們感興趣的對象屬性���,對其進行聚集����,同類的對象之間相似度高�,不同類之間差異較大����。最大特點就是事先不確定類別����。
這其中最經典的算法就是KMeans算法��,這是最常用的聚類算法�����,主要思想是:在給定K值和K個初始類簇中心點的情況下���,把每個點(亦即數據記錄)分到離其最近的類簇中心點所代表的類簇中���,所有點分配完畢之后���,根據一個類簇內的所有點重新計算該類簇的中心點(取平均值)����,然后再迭代的進行分配點和更新類簇中心點的步驟��,直至類簇中心點的變化很小�,或者達到指定的迭代次數���。
KMeans算法本身思想比較簡單�����,但是合理的確定K值和K個初始類簇中心點對于聚類效果的好壞有很大的影響�。
聚類算法實現
假設對象集合為D�,準備劃分為k個簇�����。
基本算法步驟如下:
1��、從D中隨機取k個元素�,作為k個簇的各自的中心�。
2����、分別計算剩下的元素到k個簇中心的相異度�,將這些元素分別劃歸到相異度最低的簇��。
3�����、根據聚類結果���,重新計算k個簇各自的中心��,計算方法是取簇中所有元素各自維度的算術平均數���。
4���、將D中全部元素按照新的中心重新聚類����。
5���、重復第4步�����,直到聚類結果不再變化����。
6�����、將結果輸出��。
核心Java代碼如下:
/**
* 迭代計算每個點到各個中心點的距離���,選擇最小距離將該點劃入到合適的分組聚類中�����,反復進行����,直到
* 分組不再變化或者各個中心點不再變化為止��。
* @return
*/
public List[] comput() {
List[] results = new ArrayList[k];//為k個分組���,分別定義一個聚簇集合�����,未來放入元素�。
boolean centerchange = true;//該變量存儲中心點是否發生變化
while (centerchange) {
iterCount++;//存儲迭代次數
centerchange = false;
for (int i = 0; i < k; i++) {
results[i] = new ArrayList<T>();
}
for (int i = 0; i < players.size(); i++) {
T p = players.get(i);
double[] dists = new double[k];
for (int j = 0; j < initPlayers.size(); j++) {
T initP = initPlayers.get(j);
/* 計算距離 這里采用的公式是兩個對象相關屬性的平方和�����,最后求開方*/
double dist = distance(initP, p);
dists[j] = dist;
}
int dist_index = computOrder(dists);//計算該點到各個質心的距離的最小值��,獲得下標
results[dist_index].add(p);//劃分到對應的分組����。
}
/*
* 將點聚類之后��,重新尋找每個簇的新的中心點�����,根據每個點的關注屬性的平均值確立新的質心����。
*/
for (int i = 0; i < k; i++) {
T player_new = findNewCenter(results[i]);
System.out.println("第"+iterCount+"次迭代�,中心點是:"+player_new.toString());
T player_old = initPlayers.get(i);
if (!IsPlayerEqual(player_new, player_old)) {
centerchange = true;
initPlayers.set(i, player_new);
}
}
}
return results;
}
上面代碼是其中核心代碼����,我們根據對象集合List和提前設定的k個聚集,最終完成聚類�。我們測試一下��,假設要測試根據NBA球員的場均得分情況���,進行得分高中低的聚集�����,很簡單��,高得分在一組����,中等一組����,低得分一組�����。
我們定義一個Player類����,里面有屬性goal����,并錄入數據��。并設定分組數目為k=3���。
測試代碼如下:
List listPlayers = new ArrayList();
Player p1 = new Player();
p1.setName(“mrchi1”);
p1.setGoal(1);
p1.setAssists(8);
listPlayers.add(p1);
Player p2 = new Player();
p2.setName("mrchi2");
p2.setGoal(2);
listPlayers.add(p2);
Player p3 = new Player();
p3.setName("mrchi3");
p3.setGoal(3);
listPlayers.add(p3);
//其他對象定義此處略�����。制造幾個球員的對象即可����。
Kmeans<Player> kmeans = new Kmeans<Player>(listPlayers, 3);
List<Player>[] results = kmeans.comput();
for (int i = 0; i < results.length; i++) {
System.out.println("類別" + (i + 1) + "聚集了以下球員:");
List<Player> list = results[i];
for (Player p : list) {
System.out.println(p.getName() + "--->" + p.getGoal()
}
}
算法運行結果:
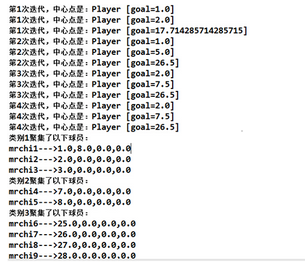
可以看出中心點經歷了四次迭代變化�,最終分類結果也確實是相近得分的分到了一組���。當然這種算法有缺點���,首先就是初始的k個中心點的確定非常重要�,結果也有差異��??梢赃x擇彼此距離盡可能遠的K個點�����,也可以先對數據用層次聚類算法進行聚類�,得到K個簇之后�,從每個類簇中選擇一個點�,該點可以是該類簇的中心點���,或者是距離類簇中心點最近的那個點�����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
