python 實例簡述 k-近鄰算法的基本原理
首先我們一個樣本集合��,也稱為訓練樣本集�����,在訓練樣本集中每個數據都存在一個標簽用來指明該數據的所屬分類��。在輸入一個新的未知所屬分類的數據后��,將新數據的所有特征和樣本集中的所有數據計算距離��。從樣本集中選擇與新數據距離最近的 k 個樣本��,將 k 個樣本中出現頻次最多的分類作為新數據的分類��,通常 k 是小于20的�,這也是 k 的出處�����。
k近鄰算法的優點:精度高�,對異常值不敏感��,無數據輸入假定����。
k 近鄰算法的缺點:時間復雜度和空間復雜度高
數據范圍:數值型和標稱型
簡單的k 近鄰算法實現
第一步:使用 python 導入數據
from numpy import *
import operator
'''simple kNN test'''
#get test data
def createDataSet():
group=array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels=['A','A','B','B']
return group,labels
作為例子�,直接創建數據集和標簽�,實際應用中往往是從文件中讀取數據集和標簽����。array 是 numpy 提供的一種數據結構�����,用以存儲同樣類型的數據���,除了常規數據類型外�,其元素也可以是列表和元組�����。這里 group 就是元素數據類型為 list 的數據集���。labels 是用列表表示的標簽集合�����。其中 group 和 labels 中的數據元素一一對應���,比如數據點[1.0,1.1]標簽是 A���,數據點[0,0.1]標簽是 B�。
第二步:實施 kNN 算法
kNN 算法的自然語言描述如下:
1. 計算已知類別數據集中的所有點與未分類點之間的距離����。
2. 將數據集中的點按照與未分類點的距離遞增排序����。
3. 選出數據集中的與未分類點間距離最近的 n 個點�����。
4. 統計這 n 個點中所屬類別出現的頻次�����。
5. 返回這 n 個點中出現頻次最高的那個類別����。
實現代碼:
def classify0(inX,dataSet,labels,k):
dataSetSize=dataSet.shape[0]
diffMat=tile(inX,(dataSetSize,1))-dataSet
sqDiffMat=diffMat**2
sqDistances=sqDiffMat.sum(axis=1)
distances=sqDistances**0.5
sortedDistIndicies=distances.argsort()
classCount={}
for i in range(k):
voteIlabel=labels[sortedDistIndicies[i]]
classCount[voteIlabel]=classCount.get(voteIlabel,0)+1
sortedClassCount=sorted(classCount.iteritems(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
classify0函數中的四個參數含義分別如下:inX 是希望被分類的數據點的屬性向量��,dataSet 是訓練數據集向量��,labels 是標簽向量��,k 是 kNN 算法的參數 k��。
接下來來看看本函數的語句都做了那些事����。
第一行dataSetSize=dataSet.shape[0]��,dataSet 是 array 類型�����,那么dataSet.shape表示 dataSet 的維度矩陣��,dataSet.shape[0]表示第二維的長度�,dataSet.shape[1]表示第一維的長度�����。在這里dataSetSize 表示訓練數據集中有幾條數據�。
第二行tile(inX,(dataSetSize,1))函數用以返回一個將 inX 以矩陣形式重復(dataSetSize,1)遍的array�����,這樣產生的矩陣減去訓練數據集矩陣就獲得了要分類的向量和每一個數據點的屬性差����,也就是 diffMat����。
第三行**在 python 中代表乘方��,那么sqDiffMat也就是屬性差的乘方矩陣���。
第四行array 的 sum 函數若是加入 axis=1的參數就表示要將矩陣中一行的數據相加����,這樣�,sqDistances的每一個數據就代表輸入向量和訓練數據點的距離的平方了�。
第五行不解釋�,得到了輸入向量和訓練數據點的距離矩陣�����。
第六行sortedDistIndicies=distances.argsort()�����,其中 argsort 函數用以返回排序的索引結果��,直接使用 argsort 默認返回第一維的升序排序的索引結果�����。
然后創建一個字典�����。
接下來進行 k 次循環��,每一次循環中����,找到 i 對應的數據的標簽��,并將其所在字典的值加一�����,然后對字典進行遞減的按 value 的排序�。
這樣循環完成后���,classCount 字典的第一個值就是kNN 算法的返回結果了��,也就是出現最多次數的那個標簽���。
二維的歐式距離公式如下�,很簡單:
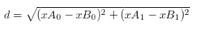
相同的��,比如說四維歐式距離公式如下:

第三步:測試分類器
在測試 kNN 算法結果的時候�����,其實就是討論分類器性能�����,至于如何改進分類器性能將在后續學習研究中探討�,現在��,用正確率來評估分類器就可以了�����。完美分類器的正確率為1�,最差分類器的正確率為0�����,由于分類時類別可能有多種�,注意在分類大于2時����,最差分類器是不能直接轉化為完美分類器的���。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
