R語言獲取優化的k均值聚類
k均值算法效率快也易于實現����,但在算法開始要求提前規定好簇K的數目��,因此我們可以使用距離的平方和確定那個K值能夠得到最好的k均值聚類效果�����。
操作
執行以下操作為K均值算法找到最合適的聚類個數
nk = 2:10
set.seed(22)
WSS = sapply(nk, function(nk){
kmeans(customer,centers = nk)$tot.withinss
})
WSS
[1] 123.49224 88.07028 61.34890 48.76431 47.20813 45.48114 29.58014 28.87519 23.21331
調用plot繪制不同的k值下距離平方和的線圖:
plot(nk,WSS,type = "l",xlab = "number of k",ylab = "within sum of squares")
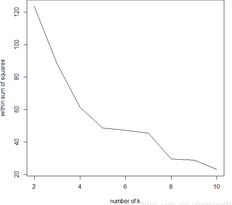
不同k值下距離平方和線圖
計算不同聚類結果的平均輪廓值(avg.silwidth)
SW =sapply(nk, function(k){
cluster.stats(dist(customer),kmeans(customer,centers = k)$cluster)$avg.silwidth
})
SW
[1] 0.4203896 0.4092890 0.4640587 0.4308448 0.4160309 0.4241364 0.3637102 0.3540200 0.3436709
不同k值的平均輪廓線
plot(nk,SW,type = "l",xlab = "number of clusers",ylab = "average silhouette width")
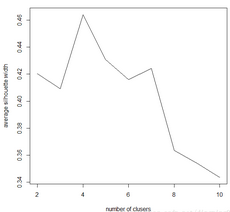
得到最大的簇個數:
nk[which.max(SW)]
原理
通過迭代生成簇的距離平方和以及平均輪廓值來尋找最優的簇數值�,其中��,距離平方和越小�����,聚簇的效果越佳�,通過不同的K值下距離平方和圖�����,可以得到最適合樣例的k值為4�����。我們還使用cluster.stats函數來計算不同的聚類結果的平均輪廓值圖���,并繪制了相應的線圖��,從結果可以知道當k=4時�����,平均輪廓值最大����。還可以用which.max函數得到最大平均輪廓值對應的k值����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
