R描述性統計分析
概念
數據摘要��,有損地提取數據特征的過程����,包含基本統計�����,分布/累計統計����,數據特征(相關性�,周期性等)����,數據挖掘
數據有很多變量和觀測值�,可以用一些簡單表格�,圖形和少數匯總數字來描述�����。這些描述方法被稱為描述統計學��,也稱為探索性數據分析(EDA����,exploratory data analysis)
描述統計目的在于幫助展示和理解數據�����。
數據作為信息的載體����,要分析數據中包含的主要信息��,即要分析數據的主要特征�。也就是說�,要研究數據的數字特征��,包括集中位置(集中趨勢)����,分散程度(離中趨勢)和數據分布(偏態和峰態)
集中趨勢從數據中選‘典型代表’�����,‘代表是否夠典型’由離散程度檢驗
位置的度量
有些匯總統計量是描述數據“位置”的�����。其實數據的每個點都有自己的位置���,不可能一一列舉��;能做到描述數據的“中間”或“中心”在哪里��;所謂位置的度量就是用來描述定量資料的集中趨勢的統計量���,集中趨勢����,一組數據向著一個中心靠攏的程度����,也體現了數據中心所在的位置
均值
R語言函數及格式:mean(x,trim=0,na.rm=FALSE),x是對象�,如向量��,矩陣���,數組或數據框
-
當mean作用于矩陣或數值型數據框時����,返回為一個值即所有數值的平均值���;若想按行或列計算均值:apply(data,1,mean),行1列2�����;或采用colMeans(data),rowMeans(iris[,1:
3])等價于apply(iris[,1:3],2,mean)
-
trim參數�,異常值:當研究的數據中存在異常值時�,可以通過設置trim參數來調整納入計算的樣本數據來剔除異常值后再計算均值�;trim取值范圍0到0.5��,表示在計算均值前需要去掉異常值的比例(個數length(data)*trim);trim參數是對排序后的數據從頭到尾剔除相同個數元素再求均值的����。
- na.rm,設置缺失值NA�����,當數據中有缺失值時需要將na.rm設置為TRUE
- weighted.mean()�,對矩陣和數組計算加權平均值���,對數據框并不適用��;格式為weighted.mean(x,wt,na.rm=FALSE),wt為權重向量與x同維度����,與時間相關的模型比較常用
幾何平均數:N個變量值乘積的N次方根�����,主要用于計算平均增長率�,比率
年收益率分別是��,4.5%,2.1%�����,平均增長率是多少��?104.5*102.1-100�����,然后再開方
sort(data):輸出排序后的元素
order(data):輸出排序后的位置
dput(data):一個神奇的函數����,輸出向量格式��,可直接復制
被濫用的均值
非單峰分布不應使用�,嬰兒和父母的平均身高加一起就是兩不靠
極值的影響
簡單的算術平均�����,增益率等不適合
中位數
中位數描述數據中心位置的數字特征�����,對于對稱分布的數據����,均值與中位數比較靠近�����;對于偏態分布的數據��,均值與中位數不同�;中位數的一個顯著特征是不受異常值的影響����,具有穩健性���,因此是非常重要的統計量
median(x,na.rm=FALSE)函數進行中位數�,要是有缺失值需要將na.rm設置為TRUE�����,sort()函數
眾數(離散變量)和分位數
眾數不受極端值的影響�����,如果數據沒有明顯的集中趨勢�����,那么眾數可能不存在����;也可能有兩個最高峰點����,那么就有兩個眾數���。眾數適用于數據量較多�����,并且數據分布偏斜程度較大有明顯峰值時
R里面竟然沒有找眾數的函數�。�����。���。����。���。

百分位數:是中位數的推廣��;p分位數又稱為100p百分位數���,0.5分位數就是中位數�,0.75分位數與0.25分位數(第75百分位數與第25百分位數)比較重要��,分別稱為上下百分四位數����,分別記為Q3����,Q1
quantile()函數計算觀測百分位數
quantile(x,probs=seq(0,1,0.25),na.rm=FALSE,),seq()產生等差數列
離散程度的測量
離散程度
一組數據原理其中心的程度
-一組變異指標�,主要用來刻畫總體分布的變異狀況或離散程度
- 數據分布的離散程度主要靠極差��,四分差��,平均差���,方差�����,標準差等統計指標來度量
- 離散程度分析的主要作用有:1)衡量平均指標的代表性�;2)反映社會經濟活動的均衡性���;3)研究總體標志值分布偏離正態分布的情況����;4)抽樣推斷統計等分析的一個基本指標
極差
樣本中兩個極端值之差��,也稱全距�����。數據越分散�,極差越大
R=xmax?xmin
極差只利用了數據兩端的信息��,容易受極端值的影響��,并沒有充分利用數列的信息
R代碼:range(data)[2]-range(data)[1] 或者 max(data)-min(data) 或者 diff(range(data))
平均差
各變量與均值差的平均數��,即平均差異�,反應一組數據的離散程度
數學性質差(不能求導)�����,未考慮數值分布
四分位差
兩個四分位點之差����,反應了中間50%數據的離散程度��,其數值越小�,說明數值越集中.
Qd=Ql?Qu
對數據掐頭去尾����,避免了極端值的影響�,但沒有充分利用數據信息
R代碼:IQR(data) 或者quantile(data)獲取各分位數據相減
方差與標準差
描述離散程度�����,最常用的指標�,它們利用了樣本的全部信息去描述數據取值的分散性����。方差是各樣本相對均值的偏差平方和的平均���,計為s2
R語言:方差var(x,na.rm=FALSE,use)�,標準差:sd(x,na.rm = FALSE), 兩者是sqrt()關系
cov()協方差矩陣��;cor()相關矩陣
Z分數,數據標準化
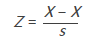
變異系數
一組數據的標準差與平均數之比�,成為變異系數�����,也叫離散系數
它是刻畫數據相對分散性的一種度量�,記為CV
相對的�,去除了單位的影響���,是無量綱統計量����,用百分號表示���。在實際應用中可以消除由于不同計量單位/不同平均水平所產生的影響
CV<-paste(round(100*sd(iris[,3])/mean(iris[,3]),2),'%',sep='')
1
偏度(Skewness)
描述某變量取值分布對稱性���,是三階矩�。
左偏分布<0�����,數據左側有一個大尾巴�����,概率密度函數中�����,有很多極小值���,均值往左邊跑���,均值小于中位數
右偏分布>0����,數據右側有一個大尾巴
對稱分布=0
峰度(Kurtosis)
描述某變量所有取值分布形態陡峭程度���,正態分布之間的較量��,標準正態分布的峰度值是3
- 正態分布(0/3)
- 尖頂峰(>0/3)
- 平頂峰(<0/3)
其他分散程度度量
css�����,校正平方和
uss��,未校正平方和
描述性統計量函數
基礎包 summary()
應用于數值型變量將分別得到位置度量指標�,即最小值min�����,上四分位數1st Qu����,中位數median�����,下四分位數3rd Qu��,最大值max����;
當應用于因子型/邏輯型向量得到頻數統計
Hmisc包中的describe()函數
可獲取缺失情況�����,唯一值����,各個詳細的分位數����,位置度量
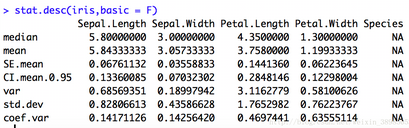
pasteccs包中的stat.desc()函數
對數值型變量進行統計分析
使用格式為stat.desc(x,basic=TRUE,desc=TRUE,norm=FALSE,p=0.95)���,basic=TRUE設置一些基礎統計參數展示���,desc可設置一些描述性統計數值的展示.desc包含中位數/平均數/平均數的標準誤/平均置信度為95%的置信區間/方差/標準差/變異系數�。
當將norm設置為TRUE時��,則返回正態分布統計量����,包括偏度和峰度(以及它們的統計顯著程度)和Shapiro-Wilk正態檢驗結果��。
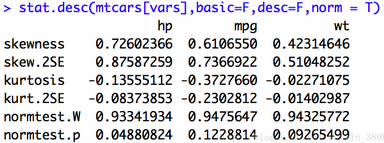
這里使用了p值來計算平均數的置信區間�,默認置信度為0.95
psych包describe()函數
可以計算非缺失值的數量���,標準差�,截尾均數����,絕對中位差�,偏度等統計量�。
偏態和峰態
反應總體分布形態的指標�,偏態(數據分布不對稱的方向和程度)��,峰態(數據分布圖形的尖峭程度或扁平程度)
分組計算描述統計量
在比較多組個體或觀測時����,關注焦點通常是各組描述性統計信息����,而不是樣本整體的描述性統計信息�����,在R中主要有三種方法可以實現:
- aggregate():分組獲取描述性統計量����,可對單組或多組變量進行分組統計���,by的變量一定要是list格式要不會報錯~按照單變量分組
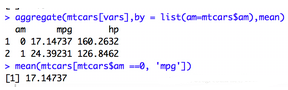
按照兩個變量作為分組,且對不給list命名即不寫‘am=’�����,跑出來的結果分組將會是Group1這種不友好的展示界面
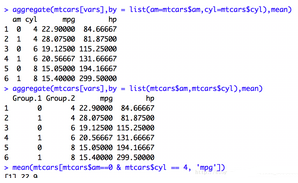
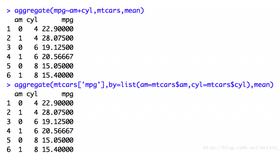
aggregate()函數的另一種寫法�����,寫成公式發~分開
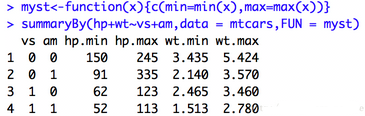
doBy包-summaryBy()函數波浪線左側為需要分析的數值型變量�,右邊為類別型分組變量�����;其中data=及FUN=不可省略不寫�;FUN可為自定義變量����,自定義函數時記得為函數起名字在展示時清楚
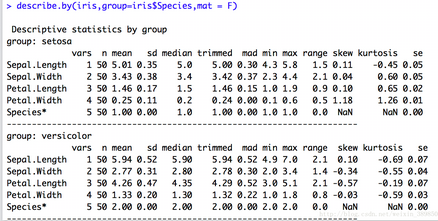
psych包中-describe.by()函數具體參數可看R幫助文檔���?describe.by()
列聯表 (頻數表)
類似excel的數據透視表
table(var1,var2…,varN):使用N個類別型變量(因子)創建一個N維列聯表
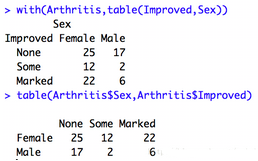
- xtabs(formula,data):xtabs(~A+B,data=mydata)
根據一個公式和一個矩陣或數據框創建一個N維列聯表;要進行交叉分類的變量應出現在公式的右側��,以+作為分隔符��。若某個變量寫在公式的左側����,則其為一個頻數向量(在數據已經被表格格式化時很有用)

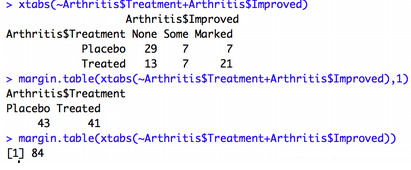
prop.table(table,margins):依margins定義的邊際列表將表中條目表示為分數形式
margin.table(table,margins):依margins定義的邊際列表計算表中條目的和,邊界求和,margin=1對行求和�,不寫總體求和
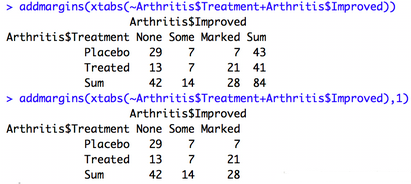
addmargins(table,margins):將概述邊margins(默認是求和結果)放入表中,margin控制加行/列的和�����,實現和excel一樣的透視表
ftable(table):創建一個緊湊的“平鋪”式列聯表
相關性分析
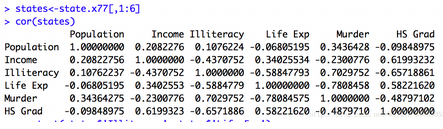
相關系數可以用來描述定量變量之間的關系�����。相關系數的符號(+����,-)表明關系的方向(正相關或負相關)���,其值的大小表明關系的強弱程度(完全不相關為0�,完全相關為1)��;相關的類型�,R可計算多種相關系數�,包括Pearson相關系數(兩個變量之間的線形相關程度)���,Spearman相關系數(分級定序變量之間的相關程度)����,Kendall相關系數(非參數的等級相關度量)��,偏相關系數�,多分格(polychoric)相關系數和多系列(polyserial)相關系數���。
散點圖�,在數據量比較少時�����,可以用散點圖觀察變量之間的關系
**
cor()函數可以計算這三種相關系數���,**cov()可以用來計算協方差��。cor(x,use=,method=),use指定缺失值處理方式����,method,指定相關系數的類型�,可選類型為pearson�����,spearman或kendall�。默認設置為everything和pearson
顯著性檢驗��,cor.test()��,來檢驗相關性的顯著水平����,cor只是計算相關性程度但沒有檢驗其顯著水平
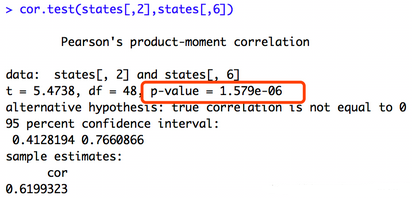
缺失值處理可選為:all.obs,假設不存在缺失數據�����,遇到缺失數據時將報錯����;everything,遇到缺失值時���,相關系數的計算結果被置為missing��;complete.obs��,行刪除�;pairwise.complete.obs�,成對刪除
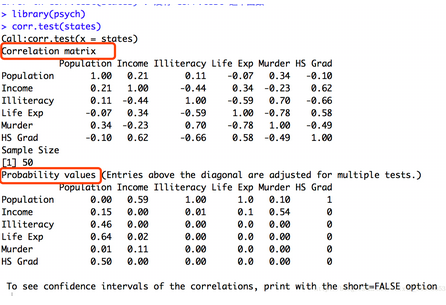
psych包中的corr.test()函數:可以一次為pearson��,Spearman����,Kendall相關計算相關矩陣和顯著性水平�����。
雙向交叉表(列聯表gmodels-crossTable()):表格中每個單元格內數量不同是由于悠然的可能性有多大
皮爾森卡方獨立性檢驗:看一個變量的值是如何隨著另一個值的變化而變化的
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
