異常檢測算法–Isolation Forest
南大周志華老師在2010年提出一個異常檢測算法Isolation Forest�,在工業界很實用�����,算法效果好�,時間效率高�����,能有效處理高維數據和海量數據��,這里對這個算法進行簡要總結��。
iTree
提到森林�����,自然少不了樹����,畢竟森林都是由樹構成的�����,看Isolation Forest(簡稱iForest)前����,我們先來看看Isolation
Tree(簡稱iTree)是怎么構成的���,iTree是一種隨機二叉樹���,每個節點要么有兩個女兒���,要么就是葉子節點�����,一個孩子都沒有��。給定一堆數據集D�����,這里D的所有屬性都是連續型的變量��,iTree的構成過程如下:
隨機選擇一個屬性Attr��;
隨機選擇該屬性的一個值Value��;
根據Attr對每條記錄進行分類����,把Attr小于Value的記錄放在左女兒����,把大于等于Value的記錄放在右孩子����;
然后遞歸的構造左女兒和右女兒����,直到滿足以下條件:
傳入的數據集只有一條記錄或者多條一樣的記錄�;
樹的高度達到了限定高度��;

iTree構建好了后����,就可以對數據進行預測啦�,預測的過程就是把測試記錄在iTree上走一下��,看測試記錄落在哪個葉子節點�����。iTree能有效檢測異常的假設是:異常點一般都是非常稀有的�,在iTree中會很快被劃分到葉子節點���,因此可以用葉子節點到根節點的路徑h(x)長度來判斷一條記錄x是否是異常點����;對于一個包含n條記錄的數據集��,其構造的樹的高度最小值為log(n)�,最大值為n-1���,論文提到說用log(n)和n-1歸一化不能保證有界和不方便比較�,用一個稍微復雜一點的歸一化公式:
s(x,n)=2(?h(x)c(n))s(x,n)=2(?h(x)c(n))
,
c(n)=2H(n?1)?(2(n?1)/n),其中H(k)=ln(k)+ξ�,ξ為歐拉常數c(n)=2H(n?1)?(2(n?1)/n),其中H(k)=ln(k)+ξ�����,ξ為歐拉常數
s(x,n)s(x,n)就是記錄x在由n個樣本的訓練數據構成的iTree的異常指數�����,s(x,n)s(x,n)取值范圍為[0,1]�����,越接近1表示是異常點的可能性高��,越接近0表示是正常點的可能性比較高���,如果大部分的訓練樣本的s(x,n)都接近于0.5��,說明整個數據集都沒有明顯的異常值����。
隨機選屬性����,隨機選屬性值�,一棵樹這么隨便搞肯定是不靠譜��,但是把多棵樹結合起來就變強大了�����;
iForest
iTree搞明白了��,我們現在來看看iForest是怎么構造的��,給定一個包含n條記錄的數據集D��,如何構造一個iForest��。iForest和Random
Forest的方法有些類似�����,都是隨機采樣一一部分數據集去構造每一棵樹����,保證不同樹之間的差異性����,不過iForest與RF不同�,采樣的數據量PsiPsi不需要等于n����,可以遠遠小于n��,論文中提到采樣大小超過256效果就提升不大了���,明確越大還會造成計算時間的上的浪費�,為什么不像其他算法一樣����,數據越多效果越好呢�,可以看看下面這兩個個圖��,
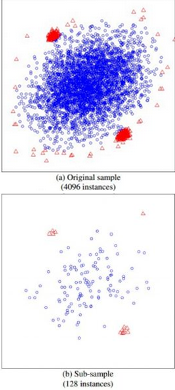
左邊是元素數據�����,右邊是采樣了數據����,藍色是正常樣本�,紅色是異常樣本��?����?梢钥吹?���,在采樣之前���,正常樣本和異常樣本出現重疊�,因此很難分開�,但我們采樣之和��,異常樣本和正常樣本可以明顯的分開���。
除了限制采樣大小以外���,還要給每棵iTree設置最大高度l=ceiling(logΨ2)l=ceiling(log2Ψ)�,這是因為異常數據記錄都比較少��,其路徑長度也比較低�,而我們也只需要把正常記錄和異常記錄區分開來�����,因此只需要關心低于平均高度的部分就好��,這樣算法效率更高�,不過這樣調整了后�,后面可以看到計算h(x)h(x)需要一點點改進��,先看iForest的偽代碼:

IForest構造好后��,對測試進行預測時�����,需要進行綜合每棵樹的結果�,于是
s(x,n)=2(?E(h(x))c(n))s(x,n)=2(?E(h(x))c(n))
E(h(x))E(h(x))表示記錄x在每棵樹的高度均值���,另外h(x)計算需要改進����,在生成葉節點時���,算法記錄了葉節點包含的記錄數量�,這時候要用這個數量SizeSize估計一下平均高度��,h(x)的計算方法如下:

處理高維數據
在處理高維數據時�,可以對算法進行改進����,采樣之后并不是把所有的屬性都用上���,而是用峰度系數Kurtosis挑選一些有價值的屬性����,再進行iTree的構造���,這跟隨機森林就更像了�����,隨機選記錄���,再隨機選屬性��。
只使用正常樣本
這個算法本質上是一個無監督學習��,不需要數據的類標�,有時候異常數據太少了����,少到我們只舍得拿這幾個異常樣本進行測試�����,不能進行訓練��,論文提到只用正常樣本構建IForest也是可行的���,效果有降低����,但也還不錯�,并可以通過適當調整采樣大小來提高效果�。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
