關聯規則評價
前面我們討論的關聯規則都是用支持度和自信度來評價的�����,如果一個規則的自信度高�����,我們就說它是一條強規則�,但是自信度和支持度有時候并不能度量規則的實際意義和業務關注的興趣點���。
一個誤導我們的強規則
看這樣一個例子�����,我們分析一個購物籃數據中購買游戲光碟和購買影片光碟之間的關聯關系����。交易數據集共有10,000條記錄�����,其中購買6000條包含游戲光碟�����,7500條包含影片光碟�����,4000條既包含游戲光碟又包含影片光碟����。數據集如下表所示:
|
買游戲
|
不買游戲
|
行總計
|
|
買影片
|
4000
|
3500
|
7500
|
|
不買影片
|
2000
|
500
|
2500
|
|
列總計
|
6000
|
4000
|
10000
|
假設我們設置得最小支持度為30%����,最小自信度為60%�����。從上面的表中����,可以得到:support(買游戲光碟—>買影片光碟)=4000/10000=40%���,confidence(買游戲光碟—>買影片光碟)=4000/7500*100%=66%(寫錯了����,應該是4000/6000)��。這條規則的支持度和自信度都滿足要求�����,因此我們很興奮��,我們找到了一條強規則����,于是我們建議超市把影片光碟和游戲光碟放在一起���,可以提高銷量�����。
可是我們想想����,一個喜歡的玩游戲的人會有時間看影片么��,這個規則是不是有問題����,事實上這條規則誤導了我們��。在整個數據集中買影片光碟的概率p(買影片)=7500/10000=75%��,而買游戲的人也買影片的概率只有66%��,66%<75%恰恰說明了買游戲光碟抑制了影片光碟的購買��,也就是說買了游戲光碟的人更傾向于不買影片光碟���,這才是符合現實的�。
從上面的例子我們看到���,支持度和自信度并不能過成功濾掉那些我們不感興趣的規則�,因此我們需要一些新的評價標準��,下面介紹六中評價標準:相關性系數�����,卡方指數�����,全自信度���、最大自信度��、Kulc���、cosine距離���。
相關性系數lift
從上面游戲和影片的例子中��,我們可以看到游戲和影片不是正相關的�,因此用相關性度量關聯規則可以過濾這樣的規則��,對于規則A—>B或者B—>A�����,lift(A,B)=P(A交B)/(P(A)*P(B))��,如果lift(A,B)>1表示A�����、B呈正相關���,lift(A,B)<1表示A���、B呈負相關���,lift(A,B)=1表示A�、B不相關(獨立)���。實際運用中���,正相關和負相關都是我們需要關注的����,而獨立往往是我們不需要的�����,兩個商品都沒有相互影響也就是不是強規則��,lift(A,B)等于1的情形也很少���,一般只要接近于1我們就認為是獨立了��。
注意相關系數只能確定相關性��,相關不是因果�����,所以A—>B或者B—>A兩個規則的相關系數是一樣的�,另外lift(A,B)=P(A交B)/(P(A)*P(B))=P(A)*P(B|A)/(P(A)*P(B))=P(B|A)/P(B)=confidence(A—>B)/support(B)=confidence(B—>A)/support(A)�。
卡方系數
卡方分布是數理統計中的一個重要分布����,利用卡方系數我們可以確定兩個變量是否相關����?��?ǚ较禂档亩x:
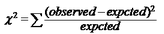
公式中的observed表示數據的實際值,expected表示期望值,不理解沒關系,我們看一個例子就明白了���。
|
買游戲
|
不買游戲
|
行總計
|
|
買影片
|
4000(4500)
|
3500(3000)
|
7500
|
|
不買影片
|
2000(1500)
|
500(1000)
|
2500
|
|
列總計
|
6000
|
4000
|
10000
|
上面表格的括號中表示的是期望值���,(買影片�,買游戲)的期望值E=6000*(7500/10000)=4500��,總體記錄中有75%的人買影片��,而買游戲的有6000人�,于是我們期望這6000人中有75%(即4500)的人買影片�����。其他三個值可以類似計算得到?,F在我們計算一下�����,買游戲與買影片的卡方系數:
卡方系數X=(4000-4500)^2/4500+(3500-3000)^2/3000+(2000-1500)^2/1500+(500-1000)^2/1000=555.6�。
卡方系數需要查表才能確定值的意義����,基于置信水平和自由度(r-1)*(c-1)=(行數-1)*(列數-1)=1����,查表得到自信度為(1-0.001)的值為6.63����,555.6大于6.63��,因此拒絕A��、B獨立的假設�����,即認為A���、B是相關的��,而expected(買影片�����,買游戲)=4500>4000,因此認為A�、B呈負相關�����。這里需要一定的概率統計知識��。如果覺得不好理解��,可以用其他的評價標準�����。
全自信度
全自信度all_confidence的定義如下:all_confidence(A,B)=P(A交B)/max{P(A),P(B)}
=min{P(B|A),P(A|B)}
=min{confidence(A—>B),confidence(B—>A)}
對于前面的例子�����,all_confidence(買游戲�,買影片)=min{confidence(買游戲—>買影片),confidence(買影片—>買游戲)}=min{66%,53.3%}=53.3%�?��?梢钥闯鋈孕哦炔皇橐粋€好的衡量標準���。
最大自信度
最大自信度則與全自信度相反��,求的不是最小的支持度而是最大的支持度����,max_confidence(A,B)=max{confidence(A—>B),confidence(B—>A)}��,不過感覺最大自信度不太實用�。
Kulc
Kulc系數就是對兩個自信度做一個平均處理:kulc(A,B)=(confidence(A—>B)+confidence(B—>A))/2�����。���,kulc系數是一個很好的度量標準��,稍后的對比我們會看到��。
cosine(A,B)
cosine(A,B)=P(A交B)/sqrt(P(A)*P(B))=sqrt(P(A|B)*P(B|A))=sqrt(confidence(A—>B)*confidence(B—>A))
七個評價準則的比較
這里有這么多的評價標準�����,究竟哪些好�����,哪些能夠準確反應事實����,我們來看一組對比�����。
|
milk
|
milk
|
行總計
|
|
coffee
|
MC
|
MC
|
C
|
|
coffee
|
MC
|
MC
|
C
|
|
列總計
|
M
|
M
|
total
|
上表中�����,M表示購買了牛奶���、C表示購買了咖啡,M表示不購買牛奶����,C表示不購買咖啡��,下面來看6個不同的數據集���,各個度量標準的值
|
數據
|
MC
|
MC
|
MC
|
MC
|
total
|
C->M自信度
|
M->C自信度
|
卡方
|
lift
|
all_conf
|
max_conf
|
Kulc
|
cosine
|
|
D1
|
10000
|
1000
|
1000
|
100000
|
112000
|
0.91
|
0.91
|
90557
|
9.26
|
0.91
|
0.91
|
0.91
|
0.91
|
|
D2
|
10000
|
1000
|
1000
|
100
|
12100
|
0.91
|
0.91
|
0
|
1.00
|
0.91
|
0.91
|
0.91
|
0.91
|
|
D3
|
100
|
1000
|
1000
|
100000
|
102100
|
0.09
|
0.09
|
670
|
8.44
|
0.09
|
0.09
|
0.09
|
0.09
|
|
D4
|
1000
|
1000
|
1000
|
100000
|
103000
|
0.50
|
0.50
|
24740
|
25.75
|
0.50
|
0.50
|
0.50
|
0.50
|
|
D5
|
1000
|
100
|
10000
|
100000
|
111100
|
0.91
|
0.09
|
8173
|
9.18
|
0.09
|
0.91
|
0.50
|
0.29
|
|
D6
|
1000
|
10
|
100000
|
100000
|
201010
|
0.99
|
0.01
|
965
|
1.97
|
0.01
|
0.99
|
0.50
|
0.10
|
我們先來看前面四個數據集D1-D4�����,從后面四列可以看出�,D1,D2中milk與coffee是正相關的���,而D3是負相關�,D4中是不相關的�,大家可能覺得���,D2的lift約等于1應該是不相關的�,事實上對比D1你會發現���,lift受MC的影響很大����,而實際上我們買牛奶和咖啡的相關性不應該取決于不買牛奶和咖啡的交易記錄����,這正是lift和卡方的劣勢���,容易受到數據記錄大小的影響��。而全自信度��、最大自信度��、Kulc�、cosine與MC無關�,它們不受數據記錄大小影響����?��?ǚ胶蚻ift還把D3判別為正相關���,而實際上他們應該是負相關����,M=100+1000=1100����,如果這1100中有超過550的購買coffee那么就認為是正相關����,而我們看到MC=100<550��,可以認為是負相關的�。
上面我們分析了全自信度����、最大自信度���、Kulc��、cosine與空值無關�����,但這幾個中哪一個更好呢�?我們看后面四個數據集D4-D6,all_conf與cosine得出相同的結果�,即D4中milk與coffee是獨立的�����,D5�����、D6是負相關的�,D5中support(C–>M)=0.91而support(M–>C)=0.09�,這樣的關系�,簡單的認為是負相關或者正相關都不妥��,Kulc做平均處理倒很好�����,平滑后認為它們是無關的�����,我們再引入一個不平衡因子IR(imbalance
ratio):
IR(A,B)=|sup(a)-sup(B)|/(sup(A)-sup(B)-sup(A交B))(注:應為(sup(A)+sup(B)-sup(A交B))
D4總IR(C,M)=0����,非常平衡�,D5中IR(C,M)=0.89,不平衡��,而D6中IR(C,M)=0.99極度不平衡���,我們應該看到Kulc值雖然相同但是平衡度不一樣���,在實際中應該意識到不平衡的可能�,根據業務作出判斷��,因此這里我們認為Kulc結合不平衡因子的是較好的評價方法����。
另外weka中還使用 Conviction和Leverage��。Conviction(A,B) = P(A)P(B)/P(AB)�, Leverage(A,B) = P(A交B)-P(A)P(B)��,Leverage是不受空值影響��,而Conviction是受空值影響的�����。
總結
本文介紹了9個關聯規則評價的準則�,其中全自信度�、最大自信度�、Kulc����、cosine����,Leverage是不受空值影響的����,這在處理大數據集是優勢更加明顯���,因為大數據中想MC這樣的空記錄更多�,根據分析我們推薦使用kulc準則和不平衡因子結合的方法
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
