基于矩陣分解的隱因子模型
推薦系統是現今廣泛運用的一種數據分析方法��。常見的如���,“你關注的人也關注他”����,“喜歡這個物品的用戶還喜歡�。�����?����!薄澳阋苍S會喜歡”等等�����。
常見的推薦系統分為基于內容的推薦與基于歷史記錄的推薦����。
基于內容的推薦�,關鍵在于提取到有用的用戶�,物品信息�,以此為特征向量來進行分類��,回歸��。
基于歷史記錄的推薦���,記錄用戶的評分�����,點擊�����,收藏等等行為�����,以此來判斷����。
基于內容的推薦對于用戶物品的信息收集度要求比較高���,而許多情況下很難得到那么多的有用信息���。而基于歷史記錄的方法�,則利用一些常見的歷史記錄�,相比與基于內容的方法���,數據的收集比較容易����。
協同過濾廣泛運用在推薦系統中�。一般的方式是通過相似性度量�,得到相似的用戶集合�����,或者相似的物品集合�,然后據此來進行推薦����。
Amazon的圖書推薦系統就是使用的基于物品相似性的推薦�����,“我猜你還喜歡**物品”��。
不過���,簡單的協同過濾效果不是很好�����,我們或考慮用戶聚類�����,得到基于用戶的協同過濾��;或只考慮物品聚類�����,得到基于物品的協同過濾��。
有人提出了基于矩陣分解(SVD)的隱因子模型(Latent Factor Model)�。
隱因子模型通過假設一個隱因子空間�,分別得到用戶�����,物品的類別矩陣��,然后通過矩陣相乘得到最后的結果�。在實踐中����,LFM的效果會高于一般的協同過濾算法��。
1. LFM基本方法
我們用user1,2,3表示用戶���,item 1,2,3表示物品���,Rij表示用戶i對于物品j的評分����,也就是喜好度���。那么我們需要得到一個關于用戶-物品的二維矩陣���,如下面的R����。
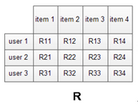
常見的系統中��,R是一個非常稀疏的矩陣�����,因為我們不可能得到所有用戶對于所有物品的評分�����。于是利用稀疏的R�����,填充得到一個滿矩陣R’就是我們的目的����。
在協同過濾中���,我們通常會假設一些用戶���,或者一些物品屬于一個類型�����,通過類型來推薦���。這這里�����,我們也可以假設類(class)��,或者說是因子(factor)�。我們假設用戶對于特定的因子有一定的喜好度�����,并且物品對于特定的因子有一定的包含度�����。
比如�����,用戶對于喜劇��,武打的喜好度為1,5���;而物品對于喜劇�����,武打的包含度為5,1��;那么我們可以大概地判斷用戶不會喜歡這部電影�����。
也就是我們人為地抽象出一個隱形因子空間�����,然后把用戶和物品分別投影到這個空間上�,來直接尋找用戶-物品的喜好度����。
一個簡單的二維隱因子空間示意圖如下:
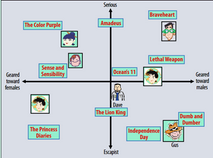
上圖以男-女���;輕松-嚴肅�����;兩個維度作為隱因子�����,把用戶和電影投影到這個二維空間上�����。
上面的問題���,我們用數學的方法描述�,就是寫成如下的矩陣:
P表示用戶對于某個隱因子的喜好度����;Q表示物品對于某個隱因子的包含度����。我們使用矩陣相乘得到用戶-物品喜好度�。

正如上面所說��,R是一個稀疏的矩陣����,我們通過R中的已知值���,得到P,Q后��,再相乘�,反過來填充R矩陣���,最后得到一個滿的R矩陣����。
于是隱因子模型轉化為矩陣分解問題���,常見的有SVD����,以及下面的一些方法����。
下面介紹具體的方法
2. Batch learning of SVD
設已知評分矩陣V����,I為索引矩陣�����,I(I,j)=1表示V中的對應元素為已知���。U����,M分別表示用戶-factor�����,物品-factor矩陣��。
于是�����,我們先用V分解為U*M����,目標函數如下:
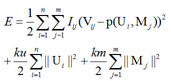
第一項為最小二乘誤差����,P可以簡單理解為點乘���;
第二項�����,第三項為防止過擬合的正則化項���。
求解上述的優化問題��,可以用梯度下降法��。計算得負梯度方向如下:
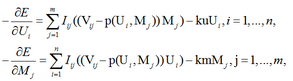
我們每次迭代�,先計算得到U�����,M的負梯度方向��,然后更新U,M�����;多次迭代�����,直至收斂���。
這種方法的缺點是對于大的稀疏矩陣來說���,有很大的方差����,要很小的收斂速度才能保證收斂��。
改進:可以考慮加入一個動量因子�����,來加速其收斂速度:
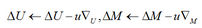
3. Incomplete incremental learning of SVD
上述的方法對于大的稀疏矩陣來說�����,不是很好的方法���。
于是��,我們細化求解過程�����。
改進后的最優化目標函數如下:
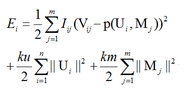
也就是���,我們以V的行為單位�,每次最優化每一行�����,從而降低batch learning的方差�����。
負梯度方向:
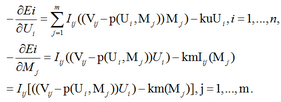
4. Complete incremental learning of SVD
同樣的�,根據incrementlearning的減少方差的思想��,我們可以再次細化求解過程�����。
以V的已知元素為單位���,求解�����。
最優化目標函數如下:
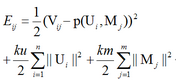
每次迭代�����,我們遍歷每個V中的已知元素��,求得一個負梯度方向���,更行U,M;
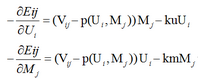
隱因子模型還有相應的其他變化版本�����,如compound SVD�,implicit feedback SVD等��,放在下一篇blog里�。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
