邁出數據分析與機器學習的第一步
數據分析太火爆���,怎奈機器學習太難懂�!隨著人工智能的浪潮卷卷襲來����,機器學習已經越來越火爆啦���。數據分析與機器學習崗位可謂供不應求���,但是入門的門檻也是蠻高的�,究竟了機器學習太難學還是咱們木有挑選到趁手的兵器呢�����?今天咱們的任務就是嘗試用Python去開啟一場數據分析和機器學習建模之旅���,用最簡單的方式帶大家邁出機器學習的第一步��!
機器學習:數據分析很好理解��,就是挖掘出來我們需要的有價值的信息����,那么機器學習又是什么呢�?剛接觸這個領域的同學可能有些迷茫����,這個詞看起來蠻高端的�����,我就來通俗的解釋一下����,機器學習也就是我們要讓機器(咱們的電腦)在歷史的數據中去學習到一些數據分布的規則然后應用到新的數據中�����,這樣新的數據來了我們就可以做一系列任務啦�����,比如銀行根據歷史數據得出來什么樣的人我會借給他多少錢���,那么一個新來的同學來借錢�����,銀行就會得出一個明確值���,借給他多少錢�!機器學習的應用已經涉及到我們生活中的各個角落啦����,隨著人工智能業的發展�,相信機器學習的力量會使得我們生活的環境更上一層樓����!
故事背景:今天要講的故事是咱們家喻戶曉的泰坦尼克號�����,那么咱們是要來回顧一下jack和rose的經典動作嗎����?這些只是咱們故事的開始����,我們要做一件非常有意思的事情�,去預測一下泰坦尼克號中�,哪些成員能獲救�。

挑選兵器:任務已經明確下達�,接下來的目的就是挑選幾個合適的兵器去進行預測的工作啦�����,咱們的主線是使用Python���,因為在數據分析與機器學習界Python已經成為一哥啦���!首先介紹下咱們的兵器譜!
Numpy-科學計算庫主要用來做矩陣運算���,什么�?你不知道哪里會用到矩陣�����,那么這樣想吧���,咱們的數據就是行(樣本)和列(特征)組成的��,那么數據本身不就是一個矩陣嘛��。
Pandas-數據分析處理庫很多小伙伴都在說用python處理數據很容易�����,那么容易在哪呢�����?其實有了pandas很復雜的操作我們也可以一行代碼去解決掉���!
Matplotlib-可視化庫無論是分析還是建模�,光靠好記性可不行�,很有必要把結果和過程可視化的展示出來��。
Scikit-Learn-機器學習庫非常實用的機器學習算法庫���,這里面包含了基本你覺得你能用上所有機器學習算法啦�。但還遠不止如此����,還有很多預處理和評估的模塊等你來挖掘的�!
數據簡介:拿上這些趁手的兵器���,我們趕緊干活吧��,首先來看一下咱們的數據是長什么樣子的���!接下來我們就用這些武器來應對問題���!
import
pandas #i
python notebook
titanic =
pandas.read_csv("titanic_train.csv")
titanic.head(5)
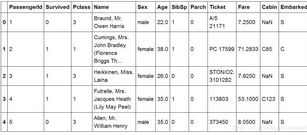
Pandas首先登場�,我們用它來進行數據處理和分析是灰常方便的���,首先讀取了.csv文件���,又顯示了它的前5行數據��。來簡單介紹一下數據中每一列都是什么意思�。
PassengerId:一個乘客的ID號�,這對我們來說好像沒啥大用呢�,獲不獲救跟ID貌似沒啥大關系�����,暫且不用它���!
Survived:這個就很重要了�����,它就是咱們的標簽(LABEL)標志著這個人到底是獲救了�,還是沒獲救�����。
Pclass:乘客的船艙等級��,是貴族還是平民呢��?有3個船艙的等級��。
Name:乘客的姓名�����,老外的名字真長啊~
Sex:只有二種~
Age:各個年齡段的都有的
SibSp:與該船員一起登船的兄弟姐妹個數
Parch:老人和孩子個數
Ticket:船票~貌似咱們用不上這個編碼
Fare:船票的價格��,貴族票還是蠻貴的
Cabin:太多的缺失值了���,直接給它pass掉不用了
Embarked:登船的碼頭�,只有3個地點
titanic["Age"] = titanic["Age"].fillna(titanic["Age"].median())
print titanic.describe()
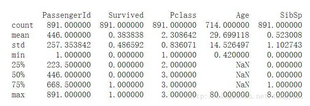
觀察可以發現�,對于Age這一列來說�����,只有714個值�����,而其他列都是891個值�,這說明了什么呢��?粗大事了��,有缺失值���,那怎么辦呢����?這可以用很多種方法啦�,用均值�����,眾數��,中位數都可以進行填充嘛�。在這里我們使用中位數來對缺失值進行了填充���。這個不是個別現象����,對于一份真實的數據來說����,缺失值是灰常常見的現象�!
print titanic["Sex"].unique()
# Replace all the occurences of male with the number 0.
titanic.loc[titanic["Sex"] == "male", "Sex"] = 0
titanic.loc[titanic["Sex"] == "female", "Sex"] = 1
['male' 'female']
再觀察一下數據�����,數據中很多列的屬性值都是字符型的��,這對我們有什么影響呢���?咱們人類可以認識這些male和female但是計算機就不認識啦�����,它只認識數值�,所以我們需要把字符值轉換成數值類型的�。
from sklearn import cross_validation
from sklearn.linear_model import LogisticRegression
# Initialize our algorithm
alg = LogisticRegression(random_state=1)
# Compute the accuracy score for all the cross validation folds. (much simpler than what we did before!)
scores = cross_validation.cross_val_score(alg, titanic[predictors], titanic["Survived"], cv=3)
# Take the mean of the scores (because we have one for each fold)
print(scores.mean())
核武器登場啦��,使用scikit-learn可以輕松建議一個機器學習模型�����,這里我們使用邏輯回歸(經典的二分類)完成這個案例���,首先還是先來介紹下邏輯回歸是什么吧���!
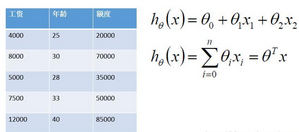
假設現在有兩個特征���,工資和年齡�。我們要根據這兩個指標來預測一下銀行會借給這個人多少錢���。那么我們就可以建立出來這樣一個方程式��!也就是說要找到最合適的一組參數使得我們最終預測的值和真實值越接近越好���!但是我們現在要做的是一個分類任務呀�!也就是說要得到一個類別值究竟是獲救了還是沒獲救�����,那么還需要往下再走一步���。
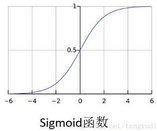
這個函數可厲害了�,我們來觀察一下���,首先這個sigmoid函數的自變量取值范圍是負無窮到正無窮的����,值域是在0到1區間上�����,那么也就是說任何一個數值進入sigmoid函數之后都會得到一個(0,1)區間上的值����,相當于是一個概率值了��,那么我們就可以設置這樣一個閾值��。比如一個概率值>0.5我們把它當成1這個類別(獲救啦)����,概率值<0.5我們把它當成0這個類別(很遺憾~)��。在木有調節任何參數的情況下精度已經接近百分之八十啦�!
模型評估:剛才咱們說了一下模型的精度��,也就是指預測的結果和真實值之間有多少個是一致的���,然后除以樣本的總個數����。精度可不是唯一的衡量標準����,在機器學習的世界���,我們有很多的標準�����,比如我們要進行一個檢測的任務�����,目的是檢測出所有病人中患癌癥的是哪幾個�����,這回就不能只用精度了而要考慮最終的目標-檢測到癌癥病人���,這回可以使用召回率(RECALL)來完成這個任務���,也就是檢測到癌癥病人個數除以癌癥病人總個數����,并不去計算正常病人我有木有檢測到�����,因為這并不是我的目標�����!
特征選擇:現在我們要好好想一想啦����,我們最終的預測結果的準確程度和什么有關呢����?一方面是我們選擇的機器學習模型另一方面還有我們輸入的特征數據呀��,所以我們還得動動腦筋什么樣的特征更適合預測呢����。腦洞大開時間到啦��,這回我們把一個成員的家庭數量也統計了出來�,就是兄弟姐妹+老人孩子��,還有名字的長度(玄學)以及稱謂Mr,Miss,Master等��。加入這些的目的就是讓我們的特征更豐富一些�,要想模型建立的好�����,特征的選擇很關鍵��,在起步階段我們需要盡可能多的提供有價值的特征���。
建立好模型還木有結束呀���,對于一個分析任務來說�,我們也需要知道這些特征對最后的結果產生了怎樣的影響�,例如是性別對結果影響比較大還是年齡呢�����?這回我們也可以通過預測的結果和真實值之間進行對比來分析一不同特征的重要程度�!下圖中可以分析得出不同特征的重要程度的差異還是蠻大的����,我們還可以進行取舍以及進一步分析啦����!
使用Matplotlib來畫一個最簡單的條形圖�,只需指定條形位置以及柱的高度即可�,要進行可視化展示我們得長和它打交道啦�!
plt.bar(range(len(predictors)), scores)
plt.xticks(range(len(predictors)), predictors, rotation='vertical')
plt.show()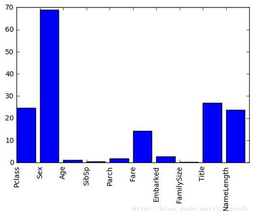
這樣咱們完成了一個灰常簡單的預測任務���,首先通過數據預處理把我們的數據做的純凈一些��,然后把這些字符值轉換成機器認識的數值���,接下來讓機器通過這批歷史數據去學習一下什么樣的參數能夠最好的擬合咱們的數據����,建立完模型后還需要不斷的反思如何調節參數能夠使得模型的效果更好以及給出一個合理的評估方法����,最終輸出來一個預測結果就完成這個機器學習的任務啦����!
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
