如何打造敏捷的數據挖掘能力
大家都知道數據挖掘是發現規律的一種手段�����,但在很多傳統企業里數據挖掘有點像奢侈品��,因為數據挖掘的過程一般較長�,總體來講性價比不是那么高���,規則取數往往成為了企業數據驅動業務的主流�����。

筆者一直在思考傳統企業敏捷數據挖掘的可能性���,這里主要從挖掘引擎��、數據準備����、訓練方法�����、迭代方式��、產品思維等方面進行闡述�,希望于你有啟示����。
1���、打造全流程挖掘引擎
諸如阿里等企業的機器學習平臺逐步形成了一個自有生態���,其機器學習引擎一般是跟企業的整個IT環境無縫集成的�����,無論是在數據準備�、數據輸入�、算法選擇���、模型訓練���、模型輸出或是生產部署等各個階段���。
商用的數據挖掘引擎則一般只能做點的事情����,強調的是算法的多樣選擇及模型訓練的可視化體驗���,在數據準備�����、數據輸入����、模型輸出��、生產發布等數據挖掘的其它階段是游離在之外的���,需要跟企業的數據環境進行交互才能完成一個數據挖掘過程�����,而這些交互一般不是自動的�����,也不具備可視化能力���,這造成了整個數據挖掘流程的割裂�,而企業在這些階段花費的代價是很大的���。
隨著一般算法使用門檻的降低�,當前商用挖掘引擎都在朝著人工智能算法+海量計算平臺化方向轉變�����,但其并不會變得更敏捷��,因為整個流程仍然是割裂的�����。
怎么辦���?
一種就是全套采用諸如阿里云的方案�,全部數據上云�����,還有一種就是自己定制����,這里談談定制方法的思路����。
所謂的定制方法就是將通用的數據挖掘引擎跟企業自身的數據開發管理平臺無縫集成���,復用原有企業的數據開發整個流程�,以下一張圖道盡了一切:
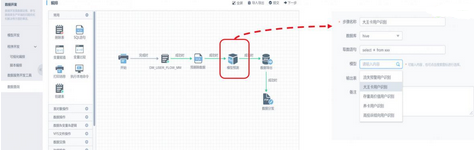
它的價值點就在于以企業的數據開發流程為核心����,而不是數據挖掘為核心�����,數據挖掘只是作為一個組件集成進來�����,比如封裝R和Python的訓練結果��,最大限度的復用原有數據管理的能力����。
因此�����,企業在采購商用數據挖掘軟件的時候��,除了考慮算法�,還要強調開放性�,要考慮是否能深度集成到自身的數據環境中��。
這是敏捷的第一個要點����。
2�、降低變量準備時間
數據挖掘中數據準備時間過長����,企業除了考慮數據倉庫建模�,還需要考慮是否在此基礎上建立一個數據挖掘的數據中臺�,筆者在《企業的數據中臺的價值》����、《數據中臺到底是什么�?》��、《如何清晰的實施“大中臺�,小前臺”
大數據運營策略���?》等文章中系統的介紹過數據中臺的價值�����,數據挖掘中臺屬于數據中臺的一部分�,行業特性會比較明顯����,比如電商有電商的數據挖掘中臺�,運營商則有運營商的數據挖掘中臺���,只要你在某個行業數據挖掘做多了���,變量準備做多了��,你自然會找到一些共性的東西���,如果能把它們沉淀下來����,就能降低變量準備時間���,比如在運營商中經常會設計平均ARPU這個變量��,但到底是三個月平均��,六個月平均還是什么����,全賴歷史經驗����。
建立數據挖掘中臺涉及IT戰略問題���,對于傳統被動型的數據管理機制流程都是挑戰���,比如要建立一支中臺團隊就不容易���。
這是敏捷的第二個要點�����。
3��、選對模型提升的方法
一般來講�,如果數據不變�,數據挖掘訓練的邊際效益并不高��,同樣的一份數據用不同的算法反復訓練���,比如F1差值并不是很大大��,如果要盡快的提升模型的效果����,要講究點方法�����,盡量遵循以下優先級:業務>數據>算法�。
沒有深刻的業務理解去做數據挖掘往往是事倍功半����,行業的業務理解越透徹�����,就越能抓住數據中本質的特征���,諸如圖像識別等場景已經可以靠神經網絡來自動查找特征了�����,但大多數行業領域不行�����,還是要靠業務專家����,多組織一次討論獲取的靈感可能遠遠好過于在算法上折騰一個月��。
沒有更多更好的數據去訓練模型����,巧婦也難為無米之炊�,一定要相信數據的重要性遠遠超過算法����,很多初級的建模師算法能力很強�,但就是做不成事�����,往往是因為其對于自身企業的數據理解太淺所致�,外來的和尚念不好經也是這個道理�。
一般企業的數據挖掘師都需要通過長時間的取數訓練����,如果能做過數據倉庫的更好���,這樣對于企業的數據體系有個全局的認識��,在特征選擇時有更多的發揮空間�,大數據中最強調的一個特征是維度多��,也一定程度說明了數據多樣的重要性�。
比如基于運營商的語音通話數據可以初步判定欺詐電話���,但這個準確率還不高��,如果加上社交網絡數據�����,判定就八九不離十了�,這就是多維數據的力量����,同時數據建模師如果不理解運營商的業務和數據�,則可能無法想到這個維度�����。
這是敏捷的第三個要點��。
4��、快速迭代及時止損
大家都知道建模需要快速迭代�����,但傳統企業中數據挖掘的快速迭代總是起不來��,原因當然很多��,包括渠道問題�����、溝通問題�,流程問題��,外包問題��,機制問題等等�����,這里筆者提一個數據挖掘“四個一”原則�����,即要為數據挖掘設置一些時間底線��。
第一個“一”是一線溝通�����,就是業務理解要跟生產人員溝通�,而不要只跟管理者溝通�,確保能夠聽到一線真實的炮聲�����。
第二個“一”是一周訓練��,整個模型的訓練需要控制在一周完成(注意不是算法研發)���,如果訓練倒騰超過一個月�����,性價比一般很低���。
第三個“一”是一周驗證���,訓練的結果要在一周內讓一線反饋結果���,傳統企業模型做不好往往是第一時間拿不到反饋數據所致�,這牽涉到企業復雜的線下執行流程���,需要在管理層面進行控制����。
第四個“一”是一周優化�����,確保能用反饋的數據進行模型的快速優化�,第三和第四反復迭代����。
當然這里的一周更多是象征意義�,企業可以基于自身的實際進行周期的調整����,關鍵是要有成本意識���,及時止損����,時間拖的越長風險越高�,因為市場變化很快�����,業務人員的耐心有限��。
這是敏捷的第四個要點�����。
5�、通過運營保有挖掘資產
據筆者統計��,離網模型在某些企業做的次數會超過幾十次�,重做有很多理由����,比如市場環境變了��,原來模型不好用了等等�,但重做意味著對原有投入資源的極大浪費�����,是最大的不敏捷����。
“重建設���,輕運營”是企業IT建設常見的毛病��,由于數據挖掘的模型受業務和數據變化的影響很大�����,隨著時間推移效果下降是必然的事情����,而且這個折損跟固定資產折損還不一樣����,人家折損好歹還能正常用��,但模型效果變差就意味著效益變差�,模型更要拼運營能力��。
從這個角度看�����,如果你覺得一個模型重要��,就要把它當成一個產品����,用產品化的思維去運營它���,比如設置獨立的模型經理����,從用戶�、流量和效果等角度去持續的做提升����,很多企業模型建完推廣完了就成鳥獸散���,這注定了模型的悲劇����。
模型運營投入的代價是巨大的����,一個有1000個挖掘模型的公司����,負擔和壓力會非常大����,如果很輕松�����,基本也就是些僵尸模型了�����。
這是敏捷的第五個要點��。
就談以上五點�����,一家之言��,但的確是感到困惑且想解決的��,希望于你有啟示���。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
