R語言之-caret包應用
caret包應用之一:數據預處理
在進行數據挖掘時�����,我們會用到R中的很多擴展包���,各自有不同的函數和功能�。如果能將它們綜合起來應用就會很方便�����。caret包(Classification
and Regression
Training)就是為了解決分類和回歸問題的數據訓練而創建的一個綜合工具包�����。下面的例子圍繞數據挖掘的幾個核心步驟來說明其應用�����。
本例涉及到的數據是一個醫學實驗數據�����,載入數據之后可以發現其樣本數為528�����,自變量數為342����,mdrrDescr為自變量數據框��,mdrrClass為因變量���。
library(caret)
data(mdrr)
本例的樣本數據所涉及到的變量非常多��,需要對變量進行初步降維��。其中一種需要刪除的變量是常數自變量���,或者是方差極小的自變量�,對應的命令是nearZeroVar���,可以看到新數據集的自變量減少到了297個����。
zerovar=nearZeroVar(mdrrDescr)
newdata1=mdrrDescr[,-zerovar]
另一類需要刪除的是與其它自變量有很強相關性的變量�,對應的命令是findcorrelation�。自變量中還有可能存在多重共線性問題��,可以用findLinearCombos命令將它們找出來����。這樣處理后自變量減少為94個�。
descrCorr = cor(newdata1)
highCorr = findCorrelation(descrCorr, 0.90)
newdata2 = newdata1[, -highCorr]
comboInfo = findLinearCombos(newdata2)
newdata2=newdata2[, -comboInfo$remove]
我們還需要將數據進行標準化并補足缺失值��,這時可以用preProcess命令�����,缺省參數是標準化數據�����,其高級功能還包括用K近鄰和裝袋決策樹兩種方法來預測缺失值��。此外它還可以進行cox冪變換和主成分提取���。
Process = preProcess(newdata2)
newdata3 = predict(Process, newdata2)
最后是用createDataPartition將數據進行劃分��,分成75%的訓練樣本和25%檢驗樣本�,類似的命令還包括了createResample用來進行簡單的自助法抽樣��,還有createFolds來生成多重交叉檢驗樣本�。
inTrain = createDataPartition(mdrrClass, p = 3/4, list = FALSE)
trainx = newdata3[inTrain,]
testx = newdata3[-inTrain,]
trainy = mdrrClass[inTrain]
testy = mdrrClass[-inTrain]
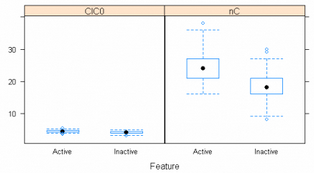
在建模前還可以對樣本數據進行圖形觀察�,例如對前兩個變量繪制箱線圖
featurePlot(trainx[,1:2],trainy,plot=’box’)
caret包應用之二:特征選擇
在進行數據挖掘時��,我們并不需要將所有的自變量用來建模�����,而是從中選擇若干最重要的變量�����,這稱為特征選擇(feature
selection)��。一種算法就是后向選擇�����,即先將所有的變量都包括在模型中��,然后計算其效能(如誤差��、預測精度)和變量重要排序��,然后保留最重要的若干變量�����,再次計算效能����,這樣反復迭代���,找出合適的自變量數目��。這種算法的一個缺點在于可能會存在過度擬合�����,所以需要在此算法外再套上一個樣本劃分的循環����。在caret包中的rfe命令可以完成這項任務��。
首先定義幾個整數�,程序必須測試這些數目的自變量.
subsets = c(20,30,40,50,60,70,80)
然后定義控制參數�����,functions是確定用什么樣的模型進行自變量排序����,本例選擇的模型是隨機森林即rfFuncs����,可以選擇的還有lmFuncs(線性回歸)�����,nbFuncs(樸素貝葉斯)���,treebagFuncs(裝袋決策樹)�,caretFuncs(自定義的訓練模型)�����。
method是確定用什么樣的抽樣方法���,本例使用cv即交叉檢驗, 還有提升boot以及留一交叉檢驗LOOCV
ctrl= rfeControl(functions = rfFuncs, method = “cv”,verbose = FALSE, returnResamp = “final”)
最后使用rfe命令進行特征選擇�,計算量很大����,這得花點時間
Profile = rfe(newdata3, mdrrClass, sizes = subsets, rfeControl = ctrl)
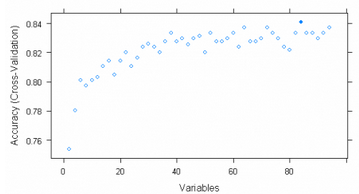
觀察結果選擇50個自變量時��,其預測精度最高
print(Profile)
Variables Accuracy Kappa AccuracySD KappaSD Selected
20 0.8200 0.6285 0.04072 0.08550
30 0.8200 0.6294 0.04868 0.10102
40 0.8295 0.6487 0.03608 0.07359
50 0.8313 0.6526 0.04257 0.08744 *
60 0.8277 0.6447 0.03477 0.07199
70 0.8276 0.6449 0.04074 0.08353
80 0.8275 0.6449 0.03991 0.08173
94 0.8313 0.6529 0.03899 0.08006
用圖形也可以觀察到同樣結果
plot(Profile)
特征選擇
下面的命令則可以返回最終保留的自變量
Profile$optVariables
caret包應用之三:建模與參數優化
在進行建模時�����,需對模型的參數進行優化���,在caret包中其主要函數命令是train��。
首先得到經過特征選擇后的樣本數據��,并劃分為訓練樣本和檢驗樣本
newdata4=newdata3[,Profile$optVariables]
inTrain = createDataPartition(mdrrClass, p = 3/4, list = FALSE)
trainx = newdata4[inTrain,]
testx = newdata4[-inTrain,]
trainy = mdrrClass[inTrain]
testy = mdrrClass[-inTrain]
然后定義模型訓練參數��,method確定多次交叉檢驗的抽樣方法�����,number確定了劃分的重數����, repeats確定了反復次數���。
fitControl = trainControl(method = “repeatedcv”, number = 10, repeats = 3,returnResamp = “all”)
確定參數選擇范圍�����,本例建模準備使用gbm算法�,相應的參數有如下四項
gbmGrid = expand.grid(.interaction.depth = c(1, 3),.n.trees = c(50,
100, 150, 200, 250, 300),.shrinkage = 0.1,.n.minobsinnode = 10)
利用train函數進行訓練���,使用的建模方法為提升決策樹方法���,
gbmFit1 = train(trainx,trainy,method = “gbm”,trControl = fitControl,tuneGrid = gbmGrid,verbose = FALSE)
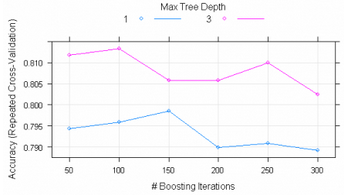
從結果可以觀察到interaction.depth取1��,n.trees取150時精度最高
interaction.depth n.trees Accuracy Kappa Accuracy SD Kappa SD
1 50 0.822 0.635 0.0577 0.118
1 100 0.824 0.639 0.0574 0.118
1 150 0.826 0.643 0.0635 0.131
1 200 0.824 0.64 0.0605 0.123
1 250 0.816 0.623 0.0608 0.124
1 300 0.824 0.64 0.0584 0.119
3 50 0.816 0.621 0.0569 0.117
3 100 0.82 0.631 0.0578 0.117
3 150 0.815 0.621 0.0582 0.117
3 200 0.82 0.63 0.0618 0.125
3 250 0.813 0.617 0.0632 0.127
3 300 0.812 0.615 0.0622 0.126
同樣的圖形觀察
plot(gbmFit1)
caret包應用之四:模型預測與檢驗
模型建立好后��,我們可以利用predict函數進行預測����,例如預測檢測樣本的前五個
predict(gbmFit1, newdata = testx)[1:5]
為了比較不同的模型���,還可用裝袋決策樹建立第二個模型����,命名為gbmFit2
gbmFit2= train(trainx, trainy,method = “treebag”,trControl = fitControl)
models = list(gbmFit1, gbmFit2)
另一種得到預測結果的方法是使用extractPrediction函數�����,得到的部分結果如下顯示
predValues = extractPrediction(models,testX = testx, testY = testy)
head(predValues)
obs pred model dataType object
1 Active Active gbm Training Object1
2 Active Active gbm Training Object1
3 Active Inactive gbm Training Object1
4 Active Active gbm Training Object1
5 Active Active gbm Training Object1
從中可提取檢驗樣本的預測結果
testValues = subset(predValues, dataType == “Test”)
如果要得到預測概率�����,則使用extractProb函數
probValues = extractProb(models,testX = testx, testY = testy)
testProbs = subset(probValues, dataType == “Test”)
對于分類問題的效能檢驗��,最重要的是觀察預測結果的混淆矩陣
Pred1 = subset(testValues, model == “gbm”)
Pred2 = subset(testValues, model == “treebag”)
confusionMatrix(Pred1$pred, Pred1$obs)
confusionMatrix(Pred2$pred, Pred2$obs)
結果如下��,可見第一個模型在準確率要比第二個模型略好一些
Reference
Prediction Active Inactive
Active 65 12
Inactive 9 45
Accuracy : 0.8397
Reference
Prediction Active Inactive
Active 63 12
Inactive 11 45
Accuracy : 0.8244
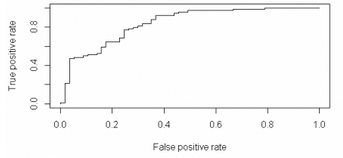
最后是利用ROCR包來繪制ROC圖
prob1 = subset(testProbs, model == “gbm”)
prob2 = subset(testProbs, model == “treebag”)
library(ROCR)
prob1$lable=ifelse(prob1$obs==’Active’,yes=1,0)
pred1 = prediction(prob1$Active,prob1$lable)
perf1 = performance(pred1, measure=”tpr”, x.measure=”fpr” )
plot( perf1 )
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
