學習機器學習時需要盡早知道的三件事
我已經在學術界和工業界進行了許多年的機器學習建模工作���,在看了一系列討論“大數據”實用性問題的優秀視頻 Scalable ML
后�����,我開始思考總結一些在學習機器學習時�,我希望能夠盡早明白的事情���。視頻來源于 Mikio Braun�����,介紹了 Scala 和 Spark
相關的知識����。
我希望在學習機器學習時能夠盡早明白的事情有三項:
-
將模型應用到產品中并不是一件簡單的小事�����;
-
在課本中我們很難學習到真正的特征選擇和特征提取技巧�����;
-
模型評估階段非常重要���。
下面讓我一個一個地介紹它們���。
1. 將模型應用到產品中并不是一件簡單的小事
我在 />
2. 在課本中我們很難學習到真正的特征選擇和特征提取技巧
特征選擇和提取方法和技巧常常無法從課本中學習�����。這些技巧只能從像 Kaggle 競賽或現實世界中的項目中學習��,甚至有時候需要實際應用這些技巧和方法才能學會它們���。而這些工作在整個數據科學項目流程中占據了相當一部分比重���。
3. 模型評估階段非常重要
除非你已經將模型應用到測試集數據上了�����,否則你都不能說已經進入到預測分析階段�。像交叉驗證��、評估指標等評估技巧都是非常寶貴的�����,因為它們只需將你的數據分離成測試集和訓練集��。但是實際生活通常并不會將已經定義好測試集�、訓練集的數據給你����,所以將真實世界中的數據劃分為測試數據和訓練數據��,是一項充滿創造性的工作�,其中可能包含許多情感因素����。在
Dato 上有許多討論模型評估的優秀文章��。
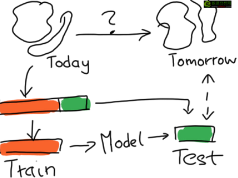
我認為 Mikio Braun 對訓練集和測試集的解釋值得一讀�。我也很喜歡他畫的圖并將其包含在文中�����,方便不熟悉訓練集和測試集概念的讀者理解�����。
我們在論文���、會議甚至在討論我們解決問題時所用的方法的時候�����,經常忽略了模型評價���?!拔覀冊谄渲惺褂昧?SVM
”這句話并沒有告訴我任何信息�����,這沒有告訴我你的數據來源��,你選擇的特征���,你的模型評估方法��,你如何將其應用到產品中�����,以及你在其中如何使用交叉驗證或模型查錯���。我認為我們需要更多關于機器學習中這些“骯臟”的方面問題的討論��。
我的朋友 Ian 在 Data Science Delivered
上有一個很好的筆記�����,適合需要為真實情況建立機器學習模型的任何層次的人員閱讀�����。同時也適合希望雇傭數據科學家的招聘人員或者與數據科學團隊打交道的經理閱讀——如果你正在找人詢問“你是如何處理這些骯臟的數據的”����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
