機器學習模型可解釋的重要及必要性
不管你是管理自己的資金還是客戶資金�,只要你在做資產管理���,每一步的投資決策都意義重大�����,做技術分析或基本面分析的朋友很清楚地知道每一個決策的細節�,但是通過機器學習�����、深度學習建模的朋友可能就會很苦惱���,因為直接產出決策信號的模型可能是個黑盒子�����,很難明白為什么模型會產出某一個信號���,甚至很多保守的私募基金把模型的可解釋性放入了事前風控��。其實�����,模型的可解釋性是很容易做到的����,難點在于研究員是否對模型有深入的思考和理解�。

介紹
機器學習領域在過去十年中發生了顯著的變化���。從一個純粹的學術和研究領域方向開始��,我們已經看到了機器學習在各個領域都有著廣泛的應用���,如零售��,技術�����,醫療保健�����,科學等等���。在21世紀�����,數據科學和機器學習的重要目標已經轉變為解決現實問題�����,自動完成復雜任務�,讓我們的生活變得更加輕松���,而不僅僅是在實驗室做實驗發表論文����。機器學習�����,統計學或深度學習模型工具已基本成型���。像Capsule Networks這樣的新模型在不斷地被提出�����,但這些新模型被工業采用卻需要幾年時間����。因此�,在工業界中���,數據科學或機器學習的主要焦點更多在于應用����,而不是理論�����。這些模型可以在正確數據上有效應用來解決現實問題是至關重要的�����。
機器學習模型本質上就是一種算法�����,該算法試圖從數據中學習潛在模式和關系�,而不是通過代碼構建一成不變的規則����。所以���,解釋一個模型是如何在商業中起作用總會遇到一系列挑戰�。在某些領域�,特別是在金融領域���,比如保險�����、銀行等�,數據科學家們通常最終不得不使用更傳統更簡單的機器學習模型(線性模型或決策樹)�。原因是模型的可解釋性對于企業解釋模型的每一個決策至關重要���。然而���,這常常導致在性能上有所犧牲�。復雜模型像如集成學習和神經網絡通常表現出更好更精準的性能(因為真實的關系在本質上很少可以通過線性劃分的)�,然而��,我們最終無法對模型決策做出合適的解釋��。為了解決和探討這些差距�����,本文中����,我會重點解釋模型可解釋性的重要及必要性��。
動機
作為一名在企業工作的數據科學家并時常指導他人��,我發現數據科學仍然常常被視為一個黑盒�,它能用“魔法”或“煉金術”提供人們想要的東西�。然而�,嚴酷的現實是���,如果不對模型進行合理足夠的解釋�����,現實世界的項目很少成功�。如今�����,數據科學家通過構建模型并為業務提供解決方案�����。企業可能不知道模型實現的復雜細節��,卻要依靠這些模型做出決策����,他們確實有權提出這樣的問題:“我怎樣才能相信你的模型����?”或“你的模型是如何決策的”����?”回答這些問題是數據科學實踐者和研究人員數年來一直在嘗試的事情���。
數據科學家知道����,模型解釋性與模型性能之前有一個權衡��。在這里��,模型性能不是運行時間或執行性能�,而是模型在做出預測時的準確度����。有幾種模型(包括簡單的線性模型甚至基于樹的模型)���,他們的預測的原理很好直觀理解����,但是需要犧牲模型性能���,因為它們的產生的結果偏差或者方差很高(欠擬合:線性模型)���,或者容易過擬合(基于樹的模型)��。更復雜的模型��,如集成模型和近期快速發展的深度學習通常會產生更好的預測性能����,但被視為黑盒模型����,因為要解釋這些模型是如何真正做出決策是一件非常困難的事情�。

雖然有些人說���,知道模型性能好就行了�,為什么還要知道它背后的原理呢��? 然而���,作為人類��,大多數決策基于邏輯和推理��。 因此�����,人工智能(AI)作出決策的模式無疑會受到懷疑���。 在很多現實情況下�����,有偏差的模型可能會產生真正的負面影響���。 這包括預測潛在的犯罪�����、司法量刑���、信用評分���、欺詐發現�、健康評估��、貸款借款�、自動駕駛等��,其中模型的理解和解釋是最重要的����。 數據科學家���、作家Cathy O’ Neil在她的著名著作《Weapons of Math Destruction》中也強調了這一點�。
著名學者和作家凱特克勞福德在NIPS 2017主題演講《The Trouble with Bias》中談到了偏差在機器學習中的影響以及它對社會的影響����。
有興趣的讀者也可以看看她在紐約時報的著名文章《 Artificial Intelligence’s White Guy Problem》����,向我們展示了機器學習應用的案例�,包括圖像分類����、犯罪風險預測�、交付服務可用性等等��,這些應用對黑人極不親善�。 如果我們想利用機器學習來解決這些問題��,所有這些真實世界的場景都在告訴我們模型解釋是多么的重要��。
在過去的一年里����,我在解決行業問題的同時也看到了對模型解釋的需求��,同時我也在寫我的新書《Practical Machine Learning with Python2》���。在這段時間里���,我有機會與DataScience.com的優秀員工進行互動��,他們非常清楚在機器學習模型中人類可解釋性的必要性和重要性���。他們也一直在積極研究解決方案��,并開發了流行的python框架Skater��。后續我們將深入研究Skater��,并在本系列文章中做一些實際的模型解釋�����。
理解模型解釋
機器學習(尤其是深度學習)僅在最近幾年才得到廣泛的行業采用����。因此��,模型解釋作為一個概念仍然主要是理論和主觀的����。
任何機器學習模型都有一個響應函數���,試圖映射和解釋自(輸入)變量和因(目標或響應)變量之間的關系和模式����。
模型解釋試圖理解和解釋響應函數做出的這些決定�����。模型解釋的關鍵在于透明度以及人們理解模型決策的容易程度�����。模型解釋的三個最重要的方面解釋如下����。
什么主導了模型預測��?我們應該找出特征的相互作用���,以了解在模型的決策策略中哪些特征可能是重要的���。這確保了模型的公平性�����。
為什么模型做出某個特定決策�?我們還應該能夠驗證為什么某些關鍵特征在預測期間推動某個模型所做出的某些決定�。這確保了模型的可靠性�����。
我們如何相信模型預測��?我們應該能夠評估和驗證任何數據點以及模型如何作出決策��。對于模型按預期運行的直接利益相關者來說����,這應該是可證明的��,并且易于理解�����。這確保了模型的透明度���。
可解釋性是指人(包括機器學習中的非專家)能夠理解模型在其決策過程中所做出的選擇(怎么決策��,為什么決策和決策了什么)�。
在模型比較時���,除了模型的性能�,如果一個模型的決策比另一個模型的決策更容易被人類理解�,則說該模型比另一個模型具有更好的可解釋性���。
模型解釋的重要性
在解決機器學習問題時����,數據科學家通常傾向于注意模型性能指標���,如準確性�、精確度和召回率等(毫無疑問��,這很重要?���。?��。但是����,度量標準只能說明模型預測性決策的一部分內容��。隨著時間的推移�����,由于環境中各種因素造成的模型概念漂移���,性能可能會發生變化�����。因此��,了解什么促使模型作出某些決定是極為重要的�。
我們中的一些人可能會認為模型已經工作得很好了��,為什么還要深入挖掘呢�?一定要記住���,當解決現實世界中的數據科學問題時����,為了讓企業相信你的模型預測和決策���,他們會不斷提問“我為什么要信任你的模型���?”�,這非常合理����。如果一個人患有癌癥或糖尿病��,如果一個人可能對社會構成風險���,或者即使客戶流失����,您是否會滿意于只是預測和做出決定(如何)的模型���?也許另外一種會更好���,如果我們可以更多地了解模型的決策過程(為什么以及如何)��,我們可能更喜歡它���。這為我們提供了更多的透明度�����,說明為什么模型會做出某些決定���,在某些情況下可能會出錯���,并且隨著時間的推移它可以幫助我們在這些機器學習模型上建立一定的信任度���。
這一部分關鍵的一點是���,現在是時候停止將機器學習模型視為黑盒子���,不僅嘗試和分析數據����,而且還要分析模型如何做出決策��。實際上�����,走向這條道路的一些關鍵步驟是由著名論文《Why Should I Trust You����?》(解釋了任意分類器的預測)”開始的���,由MT Ribeiro�,S. Singh和C. Guestrin在SIGKDD 2016上介紹了LIME(Local Interpretable Model-Agnostic Explanations)(局部可解釋模型 - 不可知論解釋)的概念�。
他們在論文中提到了一些值得記住的關鍵點��。
然而���,理解預測背后的原因在評估信任方面非常重要���,如果計劃基于預測采取行動��,或者選擇是否部署新模型��,則對模型的信任是至關重要的����。 無論人類是直接使用機器學習分類器作為工具還是在其他產品中部署模型�����,仍然存在一個至關重要的問題:如果用戶不信任模型或預測���,他們將不會使用它�。
這是我們在本文中多次討論的內容����,也是決定數據科學項目在業界成功與否的關鍵因素之一���。這就推動了模型解釋的必要性和重要性����。
模型解釋方法的標準
對于模型解釋方法的分類有特定的標準����。在Christoph Molnar的“Interpretable Machine Learning����,Making Guide for Making Black Box Models Explainable”中提到了一個很好的指導標準:
內在或事后�����?內在解釋性是關于利用機器學習模型的���,它本質上是解釋性的(像線性模型�����、參數模型或基于樹的模型)�。事后解釋性意味著選擇和訓練一個黑盒模型(集成方法或神經網絡)并在訓練后應用可解釋性方法(特征重要性����,部分依賴關系圖)�����。我們將在我們的系列文章中更多地關注事后模型可解釋的方法���。
是針對某個模型的還是通用的�����?特定于模型的解釋工具對固有模型解釋方法非常具體���,這些解釋方法完全取決于每個模型的能力和特征�。這可以是系數���,p值����,與回歸模型相關的AIC分數���,決策樹的規則等等����。通用的模型解釋方法還是依賴于事后對模型的分析��,可用于任何機器學習模型�。通常通過分析特征輸入和輸出對來運行�����。根據定義�,這些方法無法訪問任何模型內部�,如權重�����,約束或假設�����。
本地還是全局�?這種解釋的分類會談到解釋方法是解釋單個預測還是整個模型行為�?或者如果范圍介于兩者之間��?我們將盡快討論更多關于局部和全局的解釋��。
這并不是對可解釋方法進行分類的一套完整的標準����,因為這仍然是一個新興的領域���,但這可以是一個很好的標準���,可以在多種方法之間進行比較和對比���。
模型解釋的范圍
我們如何界定解釋的范圍和界限�����?一些有用的方面可以是模型的透明度��,公平性和可靠性�。本地還是全局模型解釋是定義模型解釋范圍的明確方法���。
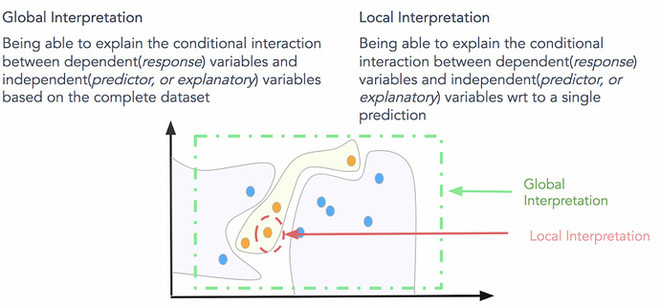
全局解釋性
這就是要試圖理解“模型如何做出預測�?”和“模型的子集如何影響模型決策�?”�。為了一次理解和解釋整個模型���,我們需要全局解釋����。全局可解釋性是指能夠基于完整數據集上的依賴(響應)變量和獨立(預測)特征之間的條件相互作用來解釋和理解模型決策����。試圖理解特征的相互作用和重要性�,往往是理解全局解釋的好的一步�。當然�,在嘗試分析交互時�����,在超過兩個或三個維度后對特征進行可視化變得非常困難�。因此�����,經常查看可能會影響全局知識模型預測的模塊化部分和特征子集�����,對全局解釋是有所幫助的��。完整的模型結構知識��,假設和約束是全局解釋所必需的��。
局部解釋性
這就是要了解“為什么模型會為單個實例做出特定決策��?”以及“為什么模型會為一組實例做出特定決策����?”�。對于局部的可解釋性�����,我們不關心模型的內在結構或假設��,我們把它當作一個黑箱子����。為了理解單個數據點的預測決策���,我們專門關注該數據點�����,并在該點附近的特征空間中查看局部子區域�����,并嘗試根據此局部區域了解該點的模型決策��。局部數據分布和特征空間可能表現完全不同��,并提供更準確的解釋而不是全局解釋�����。局部可解釋模型 - 不可知論解釋(LIME)框架是一種很好的方法��,可用于模型不可知的局部解釋����。我們可以結合使用全局解釋和局部解釋來解釋一組實例的模型決策���。
模型透明度
這就是要了解“從算法和特征中創建模型的過程如何��?”�����。我們知道���,典型的機器學習模型都是關于利用一個算法在數據特征之上構建一個表示��,將輸入映射到潛在的輸出(響應)���。模型的透明性可以嘗試理解模型如何構建的更多技術細節�,以及影響其決策的因素���。這可以是神經網絡的權值�����,CNN濾波器的權值�����,線性模型系數�����,節點和決策樹的分割�����。然而��,由于企業對這些技術細節可能并不十分熟悉�,試圖用不可知的局部和全局解釋方法來解釋模型決策有助于展示模型的透明度�。
結論
模型可解釋是一個對現實世界機器學習項目非常重要的一件事情���。讓我們試著去研究人類可解釋的機器學習�,讓每個人都打開機器學習模型的黑箱���,并幫助人們增加對模型決策的信任�。
寫在最后:模型解釋性很重要��,這能夠加深我們對模型的信心�,尤其是在金融市場中�����,當模型持續回撤時�,信心比黃金還重要�。之前有一個私募團隊使用了StockRanker策略����,但是遲遲不肯上實盤�,后來在弄清楚模型的理論原理和每一步細節�、處理流程后��,終于有信心上實盤����,實盤前期遇到回撤也能明白是正常情況�����,并非模型預測失效�,扛住前期的回撤后策略凈值開始上升���。因此�,機器學習模型可解釋很重要����,模型也是可以解釋的��,只是需要研究員付出更多的心血











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
