【數據看球】2018 年世界杯奪冠預測��,CDA帶你用機器學習來分析
隨著2018年FIFA世界杯開賽在即���,世界各地的球迷都渴望知道:誰將奪取夢寐以求的冠軍獎杯�?
如果你不僅是一名資深球迷����,而且還是技術宅�,那么你還可以利用機器學習和人工智能這兩個利器�。下面讓我們一起預測哪個國家會贏得本次世界杯����。

足球比賽涉及到很多因素����,因此許多因素無法在機器學習模型中進行探討���。這只是我作為技術宅���,從數據角度的嘗試����。
目標
1. 目標是使用機器學習預測誰將贏得2018年世界杯����。
2. 預測世界杯中每場比賽的結果���。
3. 對下場比賽進行模擬預測���,比如四分之一決賽�����,半決賽和決賽�����。
這些目標體現了現實世界中的機器學習預測問題����,當中涉及的機器學習任務包括:數據整合����,特征建模和結果預測��。
數據
我使用了Kaggle的兩個數據集�,包括自1930年起所有參賽隊在國際比賽中的結果�。
Kaggle數據集鏈接:
(https://www.kaggle.com/martj42/international-football-results-from-1872-to-2017/data)
局限性:
由于國際足聯排名創建于90年代�����,因此缺乏大部分數據集���。在此我們按照歷史比賽記錄分析���。
環境和工具:
jupyter notebook����,numpy����,pandas�,seaborn�����,matplotlib和scikit-learn�����。
我們首先要對兩個數據集進行探索性分析�����,通過特征工程選擇最相關的特征進行預測�����。之后進行數據處理���,選擇機器學習模型��,最后將其部署到數據集上�。
開始
首先��,導入必要的庫并將數據集加載到數據框�。
導入庫

加載數據集
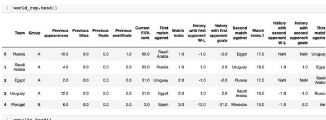
通過調用兩個數據集world_cup.head()和results.head()�,確保數據集加載到數據框中����,如下所示:
探索性分析:
對兩個數據集進行分析后��,所得數據集包含過去比賽的數據����。新產生的數據集對分析和預測之后的比賽很有用����。
在數據科學項目中�����,確定哪些特征與機器學習模型相關是最耗時的部分����。
現在�,讓我們在結果數據集中添加凈勝球數和結果列����。
查看新的結果數據框���。
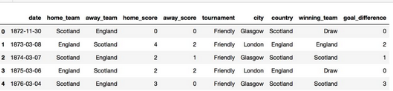
然后我們將使用數據的子集��。其中包括只有尼日利亞參加的比賽����。這將有助于我們了解某支球隊的特色����,并拓展運用到其他參賽球隊�。
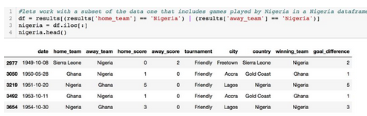
第一屆世界杯于1930年舉辦����。創建年份列���,選擇1930年以后的所有比賽�。
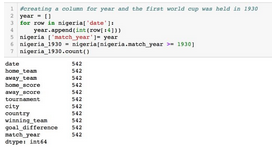
現在可以將這些年尼日利亞的比賽結果進行可視化����。
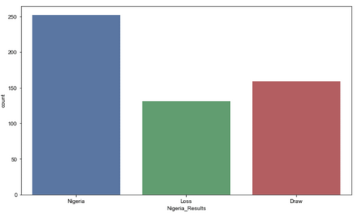
每個世界杯參賽球隊的獲勝率是很有用的指標���,我們可以用它來預測每場比賽的結果���。其中比賽場地并不重要�。
參賽球隊
對所有參賽球隊創建數據框�����。

然后進一步過濾數據框����,只顯示從1930年起到今年世界杯的球隊�����,減少重復的球隊����。

創建年份列�����,并刪除1930年之前的比賽���,以及不影響比賽結果的列���,例如日期����、主隊進球數���、客隊進球數�����、錦標賽�����、城市���、國家��、凈勝球數和比賽年份����。
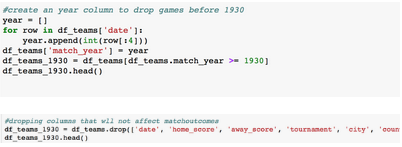
修改“Y”(預測標簽)以簡化模型處理�。
如果主隊獲勝�,獲勝隊(winner_team)列將顯示“2”��,如果是平局則顯示“1”�,如果客隊獲勝則顯示“0”��。
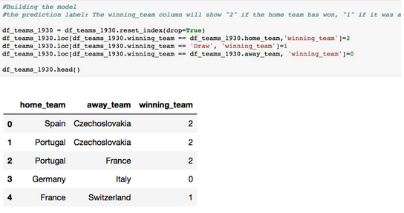
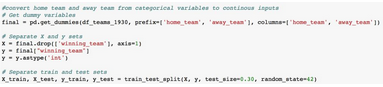
通過設置虛擬變量����,將主隊(home_team)和客隊(away _team)從分類變量轉換為連續輸入�����。
使用 pandas��,get_dummies()函數��。從而用one-hot(數字“1”和“0”)代替分類列��,確保加載到Scikit-learn模式����。
然后��,我們將X和Y集分開��,并將數據的70%用于訓練���,30%用于測試�����。
我們將使用邏輯回歸��。通過邏輯函數估計概率����,我可以測量分類因變量和一個或多個自變量之間的關系����。
換句話說�,邏輯回歸通過影響結果的數據點(統計數據)對結果進行預測(贏或輸)���。
在實際運用中�����,每次對一場比賽輸入算法��,同時提供上述“數據集”和比賽的實際結果��。然后�,模型將學習輸入數據將如何對比賽結果產生積極或消極影響�����。
讓我們看到最終數據框:
看起來很棒?��,F在加入算法:
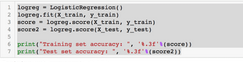
我們的模型在訓練集上的準確率為57%���,測試集的準確率為55%����。這并不理想����,但讓我們繼續���。
現在我們將創建數據框部署模型����。
首先�����,我們將加載截至到2018年4月的國際足聯排名數據集和小組賽階段的數據集���。
國際足聯排名:
(https://us.soccerway.com/teams/rankings/fifa/?ICID=TN_03_05_01)
小組賽階段數據:
(https://fixturedownload.com/results/fifa-world-cup-2018)
國際足聯排名較高的球隊將被視為“受歡迎”球隊�����。由于世界杯中不分“主隊”或“客隊”球隊���,他們都將歸屬到“home_teams”列����。然后�,根據每個團隊的排名將球隊添加到新的預測數據集中����。下一步將創建虛擬變量并部署機器學習模型�����。
預測比賽
你肯定在想什么時候才能到預測部分���。前面代碼和解釋占據了太多的篇幅���,現在我們開始預測���。
將模型部署到數據集
首先將模型部署到小組賽��。
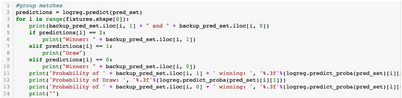
下面是小組賽的結果�。


該模型預測了三場平局����,并預測西班牙有很高的勝率�。我用這個網站預測了小組賽�。
(https://ultra.zone/2018-FIFA-World-Cup-Group-Stage)
16強
以下是對16強的預測���。
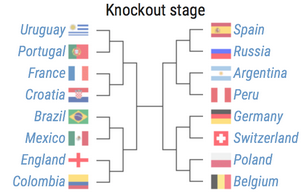

四分之一決賽
四分之一決賽的情況為:
葡萄牙vs法國���,巴西vs英格蘭�,西班牙vs阿根廷�,德國vs比利時�����。
預測結果:
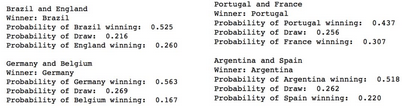
半決賽
葡萄牙vs巴西���;德國vs阿根廷
預測結果:

決賽
巴西vs德國
預測結果:巴西獲勝��。

根據模型預測�,巴西很可能贏得本次世界杯���。
結語
研究和改進空間:
1.數據集��。為了改進數據集���,你可以使用國際足聯數據來評估球隊中每個球員的水平���。
2.混淆矩陣能夠用于分析模型分析錯誤的情況�。
3.我們可以整合更多模型�,從而提高預測準確率����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
