機器學習的第一步:先學會這6種常用算法
機器學習領域不乏算法����,但眾多的算法中什么是最重要的?哪種是最適合您使用的?哪些又是互補的?使用選定資源的最佳順序是什么?今天筆者就帶大家一起來分析一下�。
通用的機器學習算法包括:
* 決策樹方法
* SVM
* 樸素貝葉斯方法
* KNN
* K均值
* 隨機森林方法
下圖是使用Python代碼和R代碼簡要說明的常見機器學習算法�����。
決策樹方法
決策樹是一種主要用于分類問題的監督學習算法���,它不僅適用于分類�����,同時也適用于連續因變量����。在這個算法中���,把種群組分為兩個或兩個以上更多的齊次集合��?;陲@著的屬性和獨立變量使群組盡可能地不同�。
Python代碼:
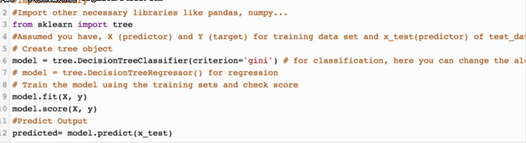
R代碼:

SVM
SVM屬于分類方法的一種��。在這個算法中��,可以將每個數據項繪制成一個n維空間中的一個點(其中n是擁有的特征數量)����,每個特征的值都是一個特定坐標的值����。例如���,我們只有兩個特征:身高和頭發長度��,首先將這兩個變量繪制在一個二維空間中��,每個點有兩個坐標(稱為支持向量)�����。然后找到一些能將兩個不同分類的數據組之間進行分割的數據�。
Python代碼:

R代碼:

樸素貝葉斯方法
這是一種基于貝葉斯定理的分類技術�,在預測變量之間建立獨立的假設����。簡而言之����,樸素貝葉斯分類器假定類中特定特征的存在與任何其他特征存在之間無關�����。樸素貝葉斯模型很容易構建�,對于大型的數據集來說�,樸素貝葉斯模型特別有用�����。最讓人心動的是����,雖然樸素貝葉斯算法很簡單����,但它的表現不亞于高度復雜的分類方法�。
貝葉斯定理提供了一種計算P(c)�����,P(x)和P(x | c)的后驗概率的方法:P(c | x)�����。
P(c | x)是給定預測器(屬性)的類(目標)的后驗概率�。
P(c)是類的先驗概率���。
P(x | c)是預測器給定類的概率的可能性�����。
P(x)是預測器的先驗概率�����。
Python代碼:

R代碼:

KNN
KNN可以用于分類和回歸問題��。但在機器學習行業中分類問題更為廣泛����。K近鄰是一種簡單的算法�,存儲所有可用的案例�,并通過其K個鄰居的投票情況來分類新案例�����。KNN方法可以很容易地映射到我們的真實生活中�����,例如想了解一個陌生人����,最好的方法可能就是從他的好朋友和生活子中獲得信息!
選擇KNN之前需要考慮的事項:
* 計算上昂貴��。
* 變量需要被標準化����,否則較高范圍的變量可能會產生偏差�。
* 在進行KNN之前�����,要進行很多預處理階段工作��。
Python代碼:

R代碼
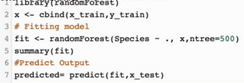
K均值
K均值是一種解決聚類問題的無監督算法�。其過程遵循一個簡單易行的方法�����,通過一定數量的集群(假設K個聚類)對給定的數據集進行分類���。集群內的數據點對同組來說是同質且異構的���。
K-均值是如何形成一個集群:
* K-均值為每個群集選取K個點��,稱為質心���。
* 每個數據點形成具有最接近的質心的群集����,即K個群集�����。
* 根據現有集群成員查找每個集群的質心����。篩選出新的質心���。
* 由于出現了有新的質心���,請重復步驟2和步驟3��,從新質心找到每個數據點的最近距離��,并與新的K個聚類關聯��。重復這個過程�����。
如何確定K的價值
在K-均值中����,我們有集群��,每個集群都有各自的質心�。集群內質心和數據點之差的平方和構成了該集群的平方和的總和���。另外��,當所有群集的平方和的總和被加上時���,它成為群集解決方案的平方和的總和�。隨著集群數量的增加�����,這個值會不斷下降���,但如果繪制結果的話���,您可能會看到�,平方距離的總和急劇下降到某個K值�����,然后會減緩下降速度��。在這里�����,可以找到最佳的集群數�。
Python代碼:

R代碼:

隨機森林方法
隨機森林是一個決策樹集合的術語�����。在隨機森林里���,我們有一系列被稱為森林的決策樹���。為了根據屬性對一個新的對象進行分類���,每棵樹都給出了一個分類���。
每棵樹形成過程如下:
* 如果訓練集中的例數為N���,則隨機抽取N個例樣本���,并進行替換���。這個樣本將成為樹生長的的訓練集���。
* 如果有M個輸入變量�,則指定一個數m << M����,從M中隨機選擇每個m變量����,并且使用m上的最佳劃分來分割節點�。在森林生長期間�����,m的值保持不變�。
* 讓每棵樹都盡可能地長到最大�����。
Python代碼:

R代碼:

CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
