決策樹剪枝的方法與必要性
1 決策樹剪枝的必要性
本文討論的決策樹主要是基于ID3算法實現的離散決策樹生成��。ID3算法的基本思想是貪心算法����,采用自上而下的分而治之的方法構造決策樹��。首先檢測訓練數據集的所有特征���,選擇信息增益最大的特征A建立決策樹根節點�,由該特征的不同取值建立分枝�,對各分枝的實例子集遞歸��,用該方法建立樹的節點和分枝�,直到某一子集中的數據都屬于同一類別����,或者沒有特征可以在用于對數據進行分割�����。ID3算法總是選擇具有最高信息增益(或最大熵壓縮)的屬性作為當前結點的測試屬性����。該屬性使得結果劃分中的樣本分類所需的信息量最小��,并反映劃分的最小隨機性或“不純性”����。這種信息理論方法使得對一個對象分類所需的期望測試數目達到最小���,并盡量確保一棵簡單的(但不必是最簡單的)樹來刻畫相關的信息��。
在ID3算法中�����,計算信息增益時���,由于信息增益存在一個內在偏置�,它偏袒具有較多值的屬性�����,太多的屬性值把訓練樣例分割成非常小的空間�。因此��,這個屬性可能會有非常高的信息增益�����,而且被選作樹的根結點的決策屬性����,并形成一棵深度只為一級但卻非常寬的樹����,這棵樹可以理想地分類訓練數據����。但是這個決策樹對于測試數據的分類性能可能會相當差�,因為它過分地完美地分割了訓練數據�����,不是一個好的分類器��。
在J.Mingers關于ID3算法的研究中��,通過對五種包含噪音的學習樣例的實驗發現����,多數情況下過度擬合導致決策樹的精度降低了10%一25%��。過度擬合不僅影響決策樹對未知實例的分類精度��,而且還會導致決策樹的規模增大�����。一方面����,葉子節點隨分割不斷增多����。在極端的情況下���,在一棵完成分割的決策樹中�����,每個葉子節點中只包含一個實例��。此時決策樹在學習樣例上的分類精度達到100%��,而其葉子節點的數目等于學習樣例中實例的數目�。但是顯然這棵決策樹對任何未見的實例都是毫無意義的�����。另一方面�,決策樹不斷向下生長�����,導致樹的深度增加����。因為每一條自根節點到葉子節點的路徑都對應一條規則�����,所以樹的深度越大���,其對應的規則越長�。作為一種蘊含于學習樣例中的知識��,這樣一組過長的規則集合是很難被人理解的�。過度擬合現象的存在���,無論是對決策樹的分類精度�����,還是對其規模以及可理解性都產生了不利的影響����。因此對與決策樹的剪枝是非常有必要的�。
2 決策樹剪枝的方法
一般情況下可以使用如下兩類方法來減小決策樹的規模:
(l)在決策樹完美分割學習樣例之前����,停止決策樹的生長���。這種提早停止樹生長的
方法�����,稱為預剪枝方法��。
(2)與預剪枝方法盡量避免過度分割的思想不同�����,一般情況下即使決策樹可能出現過度擬合現象�����,算法依然允許其充分生長����。在決策樹完全生長之后�����,通過特定標準去掉原決策樹中的某些子樹�。通常稱這種方法為后剪枝方法���。
2.1 預剪枝方法
預剪枝方法實際上是對決策樹停止標準的修改��。在原始的ID3算法中���,節點的分割一直到節點中的實例屬于同一類別時才停止��。對于包含較少實例的節點�����,可能被分割為單一實例節點����。為了避免這種情況��,我們給出一個停止閾值a��。當由一個節點分割導致的最大的不純度下降小于a時��,就把該節點看作是一個葉子節點�����。在該方法中�,閾值a的選擇對決策樹具有很大的影響���。當閾值a選擇過大時�,節點在不純度依然很高時就停止分割了�。此時由于生長不足�����,導致決策樹過小��,分類的錯誤率過高�。假設在一個兩類問題中�,根節點Root一共包含100個學習樣例����,其中正例和負例均為50����。并且使用屬性b可以將正例與負例完全分開��,即決策樹在學習樣例上的分類精度R(T)=100%����。由信息增益公式可知��,使用屬性b分割節點可以得到不純度下降的最大值0.5���。如果設a=0.7�,因為Gain(Root��,a)=0.5<0.7����,所以根節點Root不需要分割�����。此時導致決策樹在學習樣例上的分類精度下降為R(T)=50%����。當閾值a選擇過小時���,例如a近似為0����,節點的分割過程近似等同于原始的分割過程���。由此可見���,預剪枝方法雖然原理簡單��,但是在實際應用中�����,閾值a的選擇存在相當大的主觀性��。如何精確的給出適當的閾值a以獲得適當規模的決策樹是十分困難的�。
2.2后剪枝方法
決策樹是一種樹形結構�。一棵樹是一個或者多個節點的有限集合T�,使得
1.有一個特別指定的節點��,叫做樹的根節點;
2.除根節點以外�����,剩余的節點被劃分成m>=0個不相交的集合Tl��,…����,Tm����,而且每一個集合也都是樹�。樹Tl����,…�,Tm稱為這個根節點的子樹�。根據上述樹的定義��,可以直觀地將決策樹的后剪枝看作是去掉某些子樹中除根節點外所有節點的過程��,如圖1所示���。移除子樹后��,還需要對新生成的葉子節點賦予一個類別標志���,一般是葉子節點中所占比例最大的類別標志�。

圖1 決策樹剪枝過程
2.3代價復雜度剪枝
代價復雜度剪枝過程分成兩個階段:第一階段�����,首先由原決策樹通過某種剪枝策略生成一系列決策樹T0�����,Tl����,…����,Tk���。其中T����。是由決策樹生成算法推導出來的屬性決策樹����,Ti十1是依次刪除Ti的一棵或者多棵后生成的���。重復此過程���,直到最后的決策樹Tk只含有一個葉子結點�����。
第二階段��,我們對上一階段得到的決策樹進行評估����,最終選擇一棵最好的作為剪枝后的決策樹���。
考慮包含N個樣例的訓練集合�����,通過決策樹生成算法�����,如ID3�,我們可以推導出一棵屬性決策樹��。假定這棵決策樹會將其中的E個樣例錯誤分類���,再定義L(T)是決策樹T中葉子結點的數目�����,L.Breiman等人定義決策樹T的代價復雜度為

對決策樹T的一棵子樹S���,我們將能劃分到子樹S中的所有樣例的最普遍類別標簽稱之為最可能葉子�����。從原決策樹T��。開始���,為了從決策樹Ti產生Ti十1�,我們遍歷每一個非葉子子樹Ti來找到最小的a值�����,用子樹中最可能葉子代替一棵或多棵值為a的子樹��。
在第二階段��,我們從上一階段生成的一系列決策樹中���,以可靠性為標準找出一棵最好的決策樹����。如果繼續使用生成決策樹時的訓練樣例集合對決策樹的錯誤率進行評估���,觀察錯誤率可能過于樂觀��,也就是說�,對于未見樣例的錯誤率可能高于此值�����。因此��,我們使用一個單獨的測試樣例集合���,其中包含N’個樣例�,用于估計對子樹Ti的分類錯誤率���。假設E’是所有子樹Ti中最小的觀察錯誤率�����,定義E’的標準錯誤為
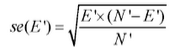
最后我們從所有子樹中選擇觀察錯誤數不超過E’+se伍’)中最小的子樹�����,作為剪枝后的子樹��。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
