R語言利用caret包比較ROC曲線
我們之前探討了多種算法�����,每種算法都有優缺點����,因而當我們針對具體問題去判斷選擇那種算法時���,必須對不同的預測模型進行重做評估�����。為了簡化這個過程�,我們使用caret包來生成并比較不同的模型與性能����。
操作
加載對應的包與將訓練控制算法設置為10折交叉驗證�����,重復次數為3:
library(ROCR)
library(e1071)
library("pROC")
library(caret)
library("pROC")
control = trainControl(method = "repaetedcv",
number = 10,
repeats =3,
classProbs = TRUE,
summaryFunction = twoClassSummary)
使用glm在訓練數據集上訓練一個分類器
glm.model = train(churn ~ .,
data= trainset,
method = "glm",
metric = "ROC",
trControl = control)
使用svm在訓練數據集上訓練一個分類器
svm.model = train(churn ~ .,
data= trainset,
method = "svmRadial",
metric = "ROC",
trControl = control)
使用rpart函數查看rpart在訓練數據集上的運行情況
rpart.model = train(churn ~ .,
data = trainset,
method = "svmRadial",
metric = "ROC",
trControl = control)
使用不同的已經訓練好的數據分類預測:
glm.probs = predict(glm.model,testset[,!names(testset) %in% c("churn")],type = "prob")
svm.probs = predict(svm.model,testset[,!names(testset) %in% c("churn")],type = "prob")
rpart.probs = predict(rpart.model,testset[,!names(testset) %in% c("churn")],type = "prob")
生成每個模型的ROC曲線�����,將它們繪制在一個圖中:
glm.ROC = roc(response = testset[,c("churn")],
predictor = glm.probs$yes,
levels = levels(testset[,c("churn")]))
plot(glm.ROC,type = "S",col = "red")
svm.ROC = roc(response = testset[,c("churn")],
predictor = svm.probs$yes,
levels = levels(testset[,c("churn")]))
plot(svm.ROC,add = TRUE,col = "green")
rpart.ROC = roc(response = testset[,c("churn")],
predictor = rpart.probs$yes,
levels = levels(testset[,c("churn")]))
plot(rpart.ROC,add = TRUE,col = "blue")
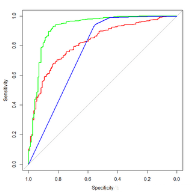
三種分類器的ROC曲線
說明
將不同的分類模型的ROC曲線繪制在同一個圖中進行比較�����,設置訓練過程的控制參數為重復三次的10折交叉驗證����,模型性能的評估參數為twoClassSummary,然后在使用glm,svm,rpart,三種不同的方法建立分類模型����。
從圖中可以看出�����,svm對訓練集的預測結果(未調優)是三種分類算法里最好的��。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
