我是R語言小白帶你建模之adaboost建模
今天更新我用我蹩腳的R技能寫的一個adaboost建模的過程���,代碼有參考別人的代碼再根據自己的思路做了更改���。代碼一部分來自書籍《實用機器學習》��,我個人特別喜歡這本書
至于adaboost�����,大家自動移步谷歌�,我跟一個人說我喜歡百度�,他誤以為我喜歡百度一個公司����,所以我決定改口說去谷歌�,畢竟谷歌沒廣告���。
先說����,模型的數據是我實現已經缺失值填補�,以及分組好的數據��,所以代碼中沒有預處理的部分����,只有一些簡單變量的轉化��。
代碼分為三部分:
1���、加載包以及一個簡單的變量形式轉化����,以及訓練集和測試的分區���,還有初步擬合一個簡單的adaboost�。
2�、設置深度以及樹的棵樹�,希望是��,能通過輸出的模型評估指標�,找到一個復雜度低��,但是模型效果相對較好的adaboost����。
3��、檢查你取的最優的adaboost的模型的泛化能力�����,這里是通過把數據集變成十等份�����,用剛才擬合出來的adaboost模型計算其ks����、auc���、正確率啊��,看時候會不會過擬合造成在其他數據集中的效果下降����。
這可能是我這么久以來這么正經的寫R代碼��,所以我的注釋特別多����,不像我的sas代碼�����,基本不寫注釋�����。
1
rm(list=ls())
# 清空緩存數據
rpart.installed <- 'rpart' %in% rownames(installed.packages())
if (rpart.installed) {
print("the rpart package is already installed, let's load it...")
}else {
print("let's install the rpart package first...")
install.packages('rpart', dependencies=T)
}
#檢查是否存在rpart包�,若沒有就加載
library('rpart')
partykit.installed <- 'partykit' %in% rownames(installed.packages())
if (partykit.installed) {
print("the partykit package is already installed, let's load it...")
}else {
print("let's install the partykit package first...")
install.packages('partykit', dependencies=T)
}
#檢查是否存在partykit包����,若沒有就加載
library('grid')
library('partykit')
adabag.installed <- 'adabag' %in% rownames(installed.packages())
if (adabag.installed) {
print("the adabag package is already installed, let's load it...")
}else {
print("let's install the adabag package first...")
install.packages('adabag', dependencies=T)
}
library('adabag')
library('rpart')
library('gplots')
library('ROCR')
# 加載在代碼中需要使用的包
x<-read.csv("alldata_zuhe.csv",header=T);
#讀目標數據��,讀取數據之前�����,手動加載路徑
D<-as.data.frame(x)
#把x數據轉成數據框
D$APPL_STATUS_1<-as.factor(D$APPL_STATUS_1)
# 把目標變量轉成因子格式��,以防模型擬合的時候識別為連續變量建立回歸樹
# colnames(D)[ncol(D)] <- 'APPL_STATUS_1'
D<-D[-which(names(D) %in% c('APPL_ID'))]
# 剔除掉一些不用進入模型的變量
train_ratio <- 0.7
# 設置訓練集以及測試集的比例���,這里設置的是3:7
n_total <- nrow(D)
# 取出原樣本數據集的數量
n_train <- round(train_ratio * n_total)
# 計算出訓練集的數量
n_test <- n_total - n_train
# 計算出測試集的數量
set.seed(42)
# 設置抽取種子�����,種子的意義在于當取同個種子的時候����,抽取的樣本一樣��。
list_train <- sample(n_total, n_train)
# 利用sample函數取數測試集的樣本的行數
D_train <- D[list_train,]
# 從原樣本中取出訓練數據
D_test <- D[-list_train,]
# 從原樣本中取出測試集數據
y_train <- D_train$APPL_STATUS_1
# 取數訓練集中的因變量�����,待會對模型的評估需要用到
y_test <- D_test$APPL_STATUS_1
# 取數測試集中的因變量���,待會對模型的評估需要用到
maxdepth <- 3
# 設置樹的深度�����,利用rpart.control帶著深度的向量���,也可以直接寫上深度�,
# 設置在提升樹過程中的樹的深度
mfinal <- 10
# 設置樹的數量
M_AdaBoost1 <- boosting(APPL_STATUS_1~., data = D_train,
boos = FALSE, mfinal = mfinal, coeflearn = 'Breiman',
control=rpart.control(maxdepth=maxdepth))
summary(M_AdaBoost1)
# 輸出對象的M_AdaBoost1的信息���,大概是種了幾棵樹����,幾個客戶預測錯了之類的�����。
M_AdaBoost1$trees
# 看下你種下的十棵樹的大致情況����。
M_AdaBoost1$trees[[1]]
# 檢查第一顆樹的情況���,你檢查也是看他合不合理��,盡管不合理��,只要效果好�����,
# 你還是會用�,畢竟又不是只有一棵樹�。
M_AdaBoost1$weights
# 檢查每棵樹的權重
M_AdaBoost1$importance
# 看下變量的重要性�����?�?梢岳眠@個方法去篩選變量��。
errorevol(M_AdaBoost1, D_test)
# 看下誤差的演變
y_test_pred_AdaBoost1 <- predict(M_AdaBoost1, D_test)
# 使用模型預測測試集的效果��。這里輸出有概率也有預測分類��,
# y_test_pred_AdaBoost1是個list的對象��,跟拒想算的模型評估量選擇計算�����。
accuracy_test_AdaBoost1 <- sum(y_test==y_test_pred_AdaBoost1$class) / n_test
# 計算正確率����,即使用預測客戶狀態
msg <- paste0('accuracy_test_AdaBoost1 = ', accuracy_test_AdaBoost1)
print(msg)
# 輸出正確率的結果
y_train_pred_AdaBoost1 <- predict(M_AdaBoost1, D_train)
# 使用模型預測訓練集的效果
accuracy_train_AdaBoost1 <- sum(y_train==y_train_pred_AdaBoost1$class) / n_train
msg <- paste0('accuracy_train_AdaBoost1 = ', accuracy_train_AdaBoost1)
print(msg)
# 計算正確率之后�����,輸出正確率的結果����。
2
# 這個代碼是為了尋找最優的種樹的數目以及深度���,因為了防止過擬合以及節省時間��,這里的深度我建議設置的是2:5
# 樹的數目大概是10-50課���,數可能多了��,但是模型復雜度也提升了�,泛化能力就低了���。
library(plyr)
# 加載需要的包
total1<-data.frame()
# 建立一個空表�����,待會這個表是用來裝結果的
m <- seq(5, 30, by = 5)
# 設置樹的數量����,我這里設置的是從5棵樹開始�,到30棵樹��,以5為單位��。
for (j in m) {
# 循環樹的數量
for(i in 3:6){
# 這里設置深度循環的數字�,我設置的3到6
maxdepth <- i
mfinal <- j
M_AdaBoost1
<- boosting(APPL_STATUS_1~., data = D_train,boos = FALSE, mfinal =
mfinal, coeflearn = 'Breiman',control=rpart.control(maxdepth=maxdepth))
# 設置參數之后生成模型
y_test_pred_AdaBoost1 <- predict(M_AdaBoost1, D_test)
# 利用生成的模型預測測試集
accuracy_test <- sum(D_test$APPL_STATUS_1==y_test_pred_AdaBoost1$class) / length(y_test_pred_AdaBoost1$class)
# 計算正確率
pred<-prediction(y_test_pred_AdaBoost1$prob[,2],y_test)
perf<-performance(pred,'tpr','fpr')
auc1 <-performance(pred,'auc')@y.values
#計算AUC值
v = as.vector(unlist(auc1[1]))
# 因為AUC值不是一個向量的格式���,但是我后續需要組成數據框�,所以在這里轉成向量了
ks1 <- max(attr(perf,'y.values')[[1]]-attr(perf,'x.values')[[1]])
#計算KS
total<-data.frame(auc=v,ks=ks1,accuracy=accuracy_test,maxdepth=i,mfinal=j)
# 將多個模型評估指標合并變成數據框
total1<-rbind(total1,total)
# 縱向合并
print(paste("adaboost-maxdepth:", i))
print(paste("adaboost-mfinal:", j))
# 打印循環哪一步�����,以防報錯的時候可以直達是哪一步錯誤�,以及跟蹤進度跑到那里了
}
}
結果跑出看total1這個數據集�����,圖:
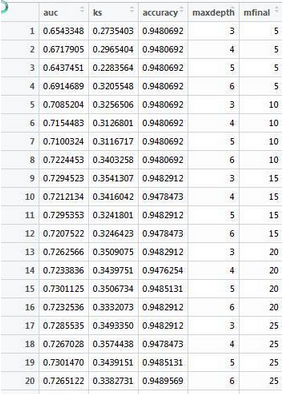
第一列是auc,依次是ks�����,正確率,設置的樹的深度����,以及種的棵樹���?���?梢愿鶕@張表選出你認為好的深度以及樹的棵樹
3
M_AdaBoost1 <- boosting(APPL_STATUS_1~., data = D_train,
boos = FALSE, mfinal = 15, coeflearn = 'Breiman',
control=rpart.control(maxdepth=3))
# 在剛才的adaboost取最優參數取出最優的樹以及深度之后���,在這里跑出模型之后���,用在其他模型上面
# 因為集成模型大部分時候都是一個類似黑箱子的過程�����,你是知道幾棵樹�,深度多少�,但是實際上���,你并不能
# 像邏輯回歸一樣一顆一顆樹去看他合不合理�,所以這時候就需要就檢查他對其他數據是不是也可行����,且效果
# 不會下降太多
library(plyr)
# 加載需要的包
CVgroup <- function(k, datasize, seed) {
cvlist <- list()
set.seed(seed)
n <- rep(1:k, ceiling(datasize/k))[1:datasize]
#將數據分成K份�,并生成的完整數據集n
temp <- sample(n, datasize)
#把n打亂
x <- 1:k
dataseq <- 1:datasize
cvlist <- lapply(x, function(x) dataseq[temp==x])
#dataseq中隨機生成10個隨機有序數據列
return(cvlist)
}
cvlist<-CVgroup(10, 10513, 957445)
# 這個過程第二個參數輸入的是你的數據集的總數����,第三個是seed種子,第一個是劃分成幾份�。
# cvlist是一個list,包含十個樣本�,每個樣本的數量差不多
data <- D
# 將的原樣本數據集賦給data
total1 <- data.frame()
#建立一個空表存儲預測結果
for (i in 1:10) {
# 循環上面那個代碼分好的是個數據集
print(i)
test <- data[cvlist[[i]],]
# 取出第i個數據集
y_test<-test$APPL_STATUS_1
# 取出第i個數據集中的因變量
y_test_pred_rf1 <- predict(M_AdaBoost1, test)
# 預測第i個數據集
accuracy_test <- sum(test$APPL_STATUS_1==y_test_pred_rf1$class) / length(y_test_pred_rf1$class)
# 計算第i個數據集的正確率
pred<-prediction(y_test_pred_rf1$prob[,2],y_test)
perf<-performance(pred,'tpr','fpr')
auc1 <- performance(pred,'auc')@y.values
v = as.vector(unlist(auc1[1]))
#計算第i個數據集的AUC值
ks1 <- max(attr(perf,'y.values')[[1]]-attr(perf,'x.values')[[1]]) #計算KS
#計算第i個數據集的ks值
total<-data.frame(auc=v,ks=ks1,accuracy=accuracy_test)
# 合并各項參數
total1<-rbind(total1,total)
# 合并每個數據集的結果
}
這個代碼跑完之后看total1,圖:
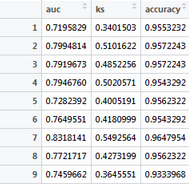
這就是你選出的模型���,將總體數據分成十份每一份的ks以及auc,你要是覺得不可靠��,可以多循環幾次種子����。要是覺得你選的模型不好���,可以回去第二步再選一個放到第三步的代碼跑���。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
