我的R語言小白之梯度上升和逐步回歸的結合使用
我們今天的主題通常在用sas擬合邏輯回歸模型的時候���,我們會使用逐步回歸�,最優得分統計模型的等方法去擬合模型�。而在接觸機器學習算法用R和python實踐之后�����,我們會了解到梯度上升算法����,和梯度下降算法��。其實本質上模型在擬合的時候用的就是最大似然估計來確定逐步回歸選出來的一個參數估計��,但是這個過程你說看不到�,那么現在假設你過程你可以選擇��,就是你來算這個最大似然估計的過程����。甚至����,你可以定義這個過程損失函數����,那么就要使用最大似然估計����。
逐步回歸法結合了向前選擇法和向后選擇法的優點����。一開始模型只有截距項����,先使用前向選擇法選入卡方統計量最大�����,符合選入模型P值的變量�����,然后使用后向選擇法移除P值最大的變量��,即最不顯著的變量�����,不斷重復以上過程���。所以也可以說逐步回歸的每一步都結合了向前選擇法和向后選擇法�。
要學習梯度上升算法和梯度下降算法����,就要先了解梯度的概念����,要了解梯度就離不開方向導數����。學過大學微積分或數學分析的同學都知道�,導數代表了一個函數的變化率����。但當一個函數包含多個自變量的時候��,函數值的變化不僅取決于自變量的變化�����,還取決于使用哪個自變量���。換句話說���,函數值同時決定于移動的距離和移動的方向����。
然后����,梯度其實就是一定最大的方向導數��。在自變量只有一個的時候��,一點的導數其實是確定的�。而到了多個自變量的時候��,以一個三維空間為例(如下圖的高山)���,概括為Y為X1�����,X2的函數���,那么在高山上的點上升的方向就不唯一��,即方向導數不唯一�,那么在某點上山最快的方向就可以描述為該點的梯度�����。在每爬到一個地方�,就不斷調整上升最快的方向���,最終就可以爬到山頂����,成為人生贏家�。在算法上就描述為每達到一個移動的步長�,就計算該點的梯度��,不斷使Y值增加��,達到最大的Y��,最后可以求得最優的X1和X2����。
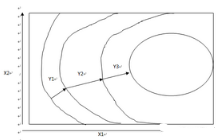
換到梯度下降法�,就可以把三維圖形想象成一個碗���,要想到碗底的話���,就應該沿下降最快的方向�����。數學上就是沒一步都求梯度的反方向����,最后目標就是求Y的最小值�����。
說了這么多�,那么梯度上升法和下降法對邏輯回歸到底有什么用呢��?邏輯回歸建模有一個目標就是求解最優的系數使似然函數最大化��。而下降法可以用來是損失函數最小化�����。先說似然函數最大化����,我們可以令模型的系數為剛才舉得例子的x1,x2即自變量����,那么我們就可以不斷迭代�����,找到最后的最大的似然函數和最佳的一組系數���。系數的梯度上升迭代式可以寫為����,下面的α就是移動的步長�����,所乘的就是梯度�。
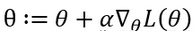
所以�,我們可以發現����,逐步回歸等算法其實優化模型的入模變量���,梯度上升法是在選定入模變量之后��,求最佳的系數去優化模型�。那么����,在實踐上我們就可以在sas擬合完模型��,選定變量后�����,在用R或者python用梯度上升法去求解最優的系數,但是需要明確一點嗎��,說是最優那是基于損失函數是一個凸函數�����,當損失函數不是凸函數的時候���,只是找到的是局部最優�����。L()這個函數是自己定義的一個損失函數組成的一個類似最大似然估計的一個函數��。
具體了解下����,還是看不懂����,可以復習一下導數��,偏導數以及方向導數����。因為梯度的內容實在有點多�����,所以還是希望大家對于梯度不了解的��,可以上網查詢了解���。我最初想用這個的時候�����,我是在想一個問題����,就是假設我不用最大似然估計定義的損失函數��,假設我想用其他損失函數擬合參數�����,那我該怎么辦��,所以才有了今天的分享�����,可能我說的優點亂�,我給出梯度擬合參數的過程���,你可能會清晰些:

那么作為R語言小白的我�����,要出動獻出我的梯度上升的代碼了�����,還是參考別人的更改�,這里的數據集使用的是你逐步回歸選下來的變量��。這里這是重新擬合參數���,不適用你原來擬合的參數���,是不是很作�,我也覺得我很作���。鏈接在這:http://blog.csdn.net/yuanhangzhegogo/article/details/40613951��。
D<-F[-which(names(F) %in% c('APPL_ID','APPL_STATUS_1'))]
# 為等下產生的樣本的矩陣做準備�����,所以把主鍵還有因變量刪掉
Y=F$APPL_STATUS_1
# 將因變量單獨拿出來���,等下要進行運算
m<-length(Y)
# 取出y的長度����,為的是等下構造截距變量����,設為1
#自變量增加一列構造矩陣
x1<-rep(1,m)
# 生成截距變量��,設為1
Y<-as.matrix(F$APPL_STATUS_1)
# 生成因變量的矩陣等下可以計算
X<-as.matrix(data.frame(x1,D))
#生成自變量矩陣����,等下計算
maxiteration=2000
#設定迭代次數
theta<-matrix(rep(0,14),ncol=1)
# 設置初始的系數
#設定學習速度
alpha=0.0001
pred<-data.frame()
# 生成一個空表
for ( n in c(1:maxiteration)){
#計算梯度
p<-1/(1+exp(-X%*%theta))
#計算通過填入參數之后的預測概率
grad=t(X)%*%(Y-p)
#放入公式計算
a<-theta
# 把前一個的參數矩陣賦給a
theta=theta+alpha*grad
# 計算梯度上升的一個參數
interval<-theta-a
# 計算之間的差值
dd<-data.frame(interval,sum=sum(interval),theta)
# 合并差值�,差值的累計���,以及對應的參數
pred<-rbind(pred,dd)
# 縱向合并每一次迭代的數據
print(n)
# 打印迭代到哪里���,好檢查錯誤以及進度
}
出來的結果看數據集看pred:
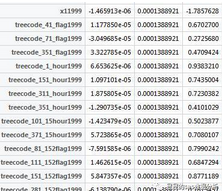
最后一列是參數估計�����,中間是兩次梯度相減的累加����,可以看到迭代了2000次之后�����,他的差距已經很小很小的�,基本可以斷定快到山頂了���,你要是覺得這樣子差距還是讓你不滿意����,你可以設置迭代次數到3000次�����。第一列是兩個梯度的各個值的相減�����,這是為了讓你看到迭代的過程該變量的權重的變小了還是變大了���。當然你也可以更改我的代碼���,把他改成迭代到兩次相減的數小于你設置的數就停止�。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
