作者 | Jason Brownlee
編譯 | CDA數據分析師
特征選擇是在開發預測模型時減少輸入變量數量的過程�����。
希望減少輸入變量的數量�����,以減少建模的計算成本�,并且在某些情況下��,還需要改善模型的性能�。
基于特征的特征選擇方法包括使用統計信息評估每個輸入變量和目標變量之間的關系�����,并選擇與目標變量關系最密切的那些輸入變量��。盡管統計方法的選擇取決于輸入和輸出變量的數據類型���,但是這些方法可以快速有效�。
這樣��,當執行基于過濾器的特征選擇時��,對于機器學習從業者來說���,為數據集選擇適當的統計量度可能是具有挑戰性的�。
在本文中����,您將發現如何為統計數據和分類數據選擇統計度量��,以進行基于過濾器的特征選擇����。
閱讀這篇文章后����,您將知道:
-
特征選擇技術主要有兩種類型:包裝器和過濾器方法����。
-
基于過濾器的特征選擇方法使用統計量度對可以過濾以選擇最相關特征的輸入變量之間的相關性或依賴性進行評分���。
-
必須根據輸入變量和輸出或響應變量的數據類型仔細選擇用于特征選擇的統計量度�����。
總覽
本教程分為三個部分:他們是:
-
特征選擇方法
-
篩選器特征選擇方法的統計信息
-
功能選擇提示和技巧
特征選擇方法旨在將輸入變量的數量減少到被認為對模型最有用的那些變量�����,以預測目標變量����。
一些預測性建模問題包含大量變量�����,這些變量可能會減慢模型的開發和訓練速度��,并需要大量的系統內存����。此外���,當包含與目標變量無關的輸入變量時�����,某些模型的性能可能會降低�����。
特征選擇算法有兩種主要類型:包裝器方法和過濾器方法�。
-
包裝功能選擇方法�����。
-
篩選功能選擇方法���。
包裝器特征選擇方法會創建許多具有不同輸入特征子集的模型�����,并根據性能指標選擇那些導致最佳性能模型的特征����。這些方法與變量類型無關���,盡管它們在計算上可能很昂貴���。RFE是包裝功能選擇方法的一個很好的例子��。
包裝器方法使用添加和/或刪除預測變量的過程來評估多個模型��,以找到使模型性能最大化的最佳組合���。
—第490頁����,應用預測建模����,2013年�����。
過濾器特征選擇方法使用統計技術來評估每個輸入變量和目標變量之間的關系���,這些分數將用作選擇(過濾)將在模型中使用的那些輸入變量的基礎���。
過濾器方法在預測模型之外評估預測變量的相關性�,然后僅對通過某些標準的預測變量進行建模�。
—第490頁���,應用預測建模����,2013年�。
通常在輸入和輸出變量之間使用相關類型統計量度作為過濾器特征選擇的基礎�����。這樣��,統計量度的選擇高度依賴于可變數據類型��。
常見的數據類型包括數字(例如高度)和類別(例如標簽)���,但是每種數據類型都可以進一步細分�����,例如數字變量的整數和浮點數�,類別變量的布爾值���,有序數或標稱值�。
常見的輸入變量數據類型:
-
數值變量
-
整數變量�����。
-
浮點變量�����。
-
分類變量
-
布爾變量(二分法)�。
-
序數變量�。
-
標稱變量���。
對變量的數據類型了解得越多�,就越容易為基于過濾器的特征選擇方法選擇適當的統計量度�。
在下一部分中����,我們將回顧一些統計量度����,這些統計量度可用于具有不同輸入和輸出變量數據類型的基于過濾器的特征選擇�。
基于過濾器的特征選擇方法的統計信息
在本節中�����,我們將考慮兩大類變量類型:數字和類別���;同樣�,要考慮的兩個主要變量組:輸入和輸出����。
輸入變量是作為模型輸入提供的變量���。在特征選擇中�����,我們希望減小這些變量的大小���。輸出變量是模型要預測的變量��,通常稱為響應變量���。
響應變量的類型通常指示正在執行的預測建模問題的類型��。例如����,數字輸出變量指示回歸預測建模問題����,而分類輸出變量指示分類預測建模問題��。
-
數值輸出:回歸預測建模問題��。
-
分類輸出:分類預測建模問題�。
通常在基于過濾器的特征選擇中使用的統計量度是與目標變量一次計算一個輸入變量�。因此�,它們被稱為單變量統計量度�。這可能意味著在過濾過程中不會考慮輸入變量之間的任何交互�����。
這些技術大多數都是單變量的���,這意味著它們獨立地評估每個預測變量����。在這種情況下��,相關預測變量的存在使選擇重要但多余的預測變量成為可能����。此問題的明顯后果是選擇了太多的預測變量���,結果出現了共線性問題���。
—第499頁��,應用預測建模����,2013年��。
使用此框架�����,讓我們回顧一些可用于基于過濾器的特征選擇的單變量統計量度�����。
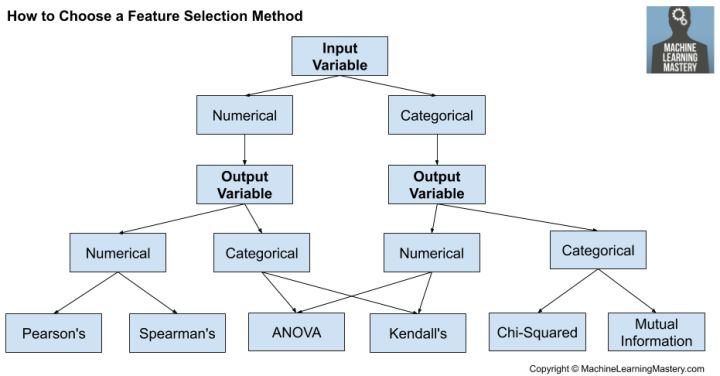
如何選擇機器學習的特征選擇方法
數值輸入�����,數值輸出
這是帶有數字輸入變量的回歸預測建模問題�。
最常見的技術是使用相關系數����,例如使用Pearson進行線性相關�����,或使用基于秩的方法進行非線性相關���。
-
皮爾遜相關系數(線性)��。
-
Spearman的秩系數(非線性)
數值輸入�����,分類輸出
這是帶有數字輸入變量的分類預測建模問題����。
這可能是最常見的分類問題示例��,
同樣����,最常見的技術是基于相關的�,盡管在這種情況下�����,它們必須考慮分類目標�。
-
方差分析相關系數(線性)�。
-
肯德爾的秩系數(非線性)����。
Kendall確實假定類別變量為序數�。
分類輸入����,數值輸出
這是帶有分類輸入變量的回歸預測建模問題��。
這是回歸問題的一個奇怪示例(例如��,您不會經常遇到它)��。
不過�����,您可以使用相同的“ 數值輸入�,分類輸出 ”方法(如上所述)�,但要相反���。
分類輸入�,分類輸出
這是帶有分類輸入變量的分類預測建模問題����。
分類數據最常見的相關度量是卡方檢驗��。您還可以使用信息論領域的互信息(信息獲?���。?���。
實際上�,互信息是一種強大的方法���,可能對分類數據和數字數據都有用����,例如��,與數據類型無關���。
功能選擇提示和技巧
使用基于過濾器的功能選擇時���,本節提供了一些其他注意事項�����。
相關統計
scikit-learn庫提供了大多數有用的統計度量的實現��。
例如:
-
皮爾遜相關系數:f_regression()
-
方差分析:f_classif()
-
Chi-Squared:chi2()
-
共同信息:Mutual_info_classif()和Mutual_info_regression()
此外�����,SciPy庫提供了更多統計信息的實現�����,例如Kendall的tau(kendalltau)和Spearman的排名相關性(spearmanr)�����。
選擇方式
一旦針對具有目標的每個輸入變量計算出統計信息��,scikit-learn庫還將提供許多不同的過濾方法�����。
兩種比較流行的方法包括:
-
選擇前k個變量:SelectKBest
-
選擇頂部的百分位數變量:SelectPercentile
我經常自己使用SelectKBest���。
轉換變量
考慮轉換變量以訪問不同的統計方法���。
例如��,您可以將分類變量轉換為序數(即使不是序數)����,然后查看是否有任何有趣的結果����。
您還可以使數值變量離散(例如����,箱)����;嘗試基于分類的度量��。
一些統計度量假設變量的屬性�����,例如Pearson假設假定觀測值具有高斯概率分布并具有線性關系�。您可以轉換數據以滿足測試的期望�,然后不管期望如何都可以嘗試測試并比較結果�。
最好的方法是什么�?
沒有最佳功能選擇方法���。
就像沒有最佳的輸入變量集或最佳的機器學習算法一樣�。至少不是普遍的�����。
相反��,您必須使用認真的系統實驗來發現最適合您的特定問題的方法�����。
嘗試通過不同的統計量度來選擇適合不同特征子集的各種不同模型�,并找出最適合您的特定問題的模型�。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情�;















 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
