作者 | Jason Brownlee
編譯 | CDA數據分析師
特征選擇是識別和選擇與目標變量最相關的輸入特征子集的過程�����。
使用實值數據(例如使用Pearson的相關系數)時��,特征選擇通常很簡單�,但是使用分類數據時可能會遇到挑戰�����。
當目標變量也是分類的(例如分類預測建模)時�,分類輸入數據的兩種最常用的特征選擇方法是卡方統計和互信息統計����。
在本教程中���,您將發現如何使用分類輸入數據執行特征選擇�����。
完成本教程后��,您將知道:
-
具有分類輸入和二元分類目標變量的乳腺癌預測建模問題���。
-
如何使用卡方和互信息統計來評估分類特征的重要性��。
-
在擬合和評估分類模型時�����,如何對分類數據執行特征選擇�����。
教程概述
本教程分為三個部分:他們是:
-
乳腺癌分類數據集
-
分類特征選擇
-
使用選定特征建模
乳腺癌分類數據集
作為本教程的基礎���,我們將使用自1980年代以來作為機器學習數據集而被廣泛研究的所謂“ 乳腺癌 ”數據集�。
該數據集將乳腺癌患者數據分類為癌癥復發或無復發�����。有286個示例和9個輸入變量���。這是一個二進制分類問題�����。
天真的模型可以在此數據集上達到70%的精度��。好的分數大約是76%+/- 3%�。我們將針對該區域����,但是請注意�����,本教程中的模型并未進行優化�。它們旨在演示編碼方案����。
您可以下載數據集���,然后將文件另存為“ breast-cancer.csv ”在當前工作目錄中���。
-
乳腺癌數據集(breast-cancer.csv)
查看數據�����,我們可以看到所有九個輸入變量都是分類的�����。
具體來說�,所有變量都用引號引起來�;有些是序數�,有些不是�����。
'40-49','premeno','15-19','0-2','yes','3','right','left_up','no','recurrence-events' '50-59','ge40','15-19','0-2','no','1','right','central','no','no-recurrence-events' '50-59','ge40','35-39','0-2','no','2','left','left_low','no','recurrence-events' '40-49','premeno','35-39','0-2','yes','3','right','left_low','yes','no-recurrence-events' '40-49','premeno','30-34','3-5','yes','2','left','right_up','no','recurrence-events' ...
我們可以使用Pandas庫將該數據集加載到內存中�����。
... # load the dataset as a pandas DataFrame data = read_csv(filename, header=None) # retrieve numpy array dataset = data.values
加載后����,我們可以將列分為輸入(X)和輸出以進行建模���。
... # split into input (X) and output (y) variables X = dataset[:, :-1] y = dataset[:,-1]
最后����,我們可以將輸入數據中的所有字段都強制為字符串����,以防萬一熊貓試圖將某些字段自動映射為數字(確實如此)���。
... # format all fields as string X = X.astype(str)
我們可以將所有這些結合到一個有用的功能中�����,以備后用�。
# load the dataset def load_dataset(filename): # load the dataset as a pandas DataFrame data = read_csv(filename, header=None) # retrieve numpy array dataset = data.values # split into input (X) and output (y) variables X = dataset[:, :-1] y = dataset[:,-1] # format all fields as string X = X.astype(str) return X, y
加載后���,我們可以將數據分為訓練集和測試集���,以便我們可以擬合和評估學習模型��。
我們將使用scikit-learn形式的traintestsplit()函數�����,并將67%的數據用于訓練�����,將33%的數據用于測試�。
... # load the dataset X, y = load_dataset('breast-cancer.csv') # split into train and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)
將所有這些元素結合在一起�,下面列出了加載��,拆分和匯總原始分類數據集的完整示例��。
# load and summarize the dataset from pandas import read_csv from sklearn.model_selection import train_test_split # load the dataset def load_dataset(filename): # load the dataset as a pandas DataFrame data = read_csv(filename, header=None) # retrieve numpy array dataset = data.values # split into input (X) and output (y) variables X = dataset[:, :-1] y = dataset[:,-1] # format all fields as string X = X.astype(str) return X, y # load the dataset X, y = load_dataset('breast-cancer.csv') # split into train and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # summarize print('Train', X_train.shape, y_train.shape) print('Test', X_test.shape, y_test.shape)
運行示例將報告訓練和測試集的輸入和輸出元素的大小���。
我們可以看到����,我們有191個示例用于培訓���,而95個用于測試�。
Train (191, 9) (191, 1) Test (95, 9) (95, 1)
既然我們已經熟悉了數據集��,那么讓我們看一下如何對它進行編碼以進行建模��。
我們可以使用scikit-learn的OrdinalEncoder()將每個變量編碼為整數���。這是一個靈活的類����,并且允許將類別的順序指定為參數(如果已知這樣的順序)����。
注意:我將作為練習來更新以下示例���,以嘗試為具有自然順序的變量指定順序�,并查看其是否對模型性能產生影響�。
對變量進行編碼的最佳實踐是使編碼適合訓練數據集���,然后將其應用于訓練和測試數據集���。
下面名為prepare_inputs()的函數獲取火車和測試集的輸入數據���,并使用序數編碼對其進行編碼�����。
# prepare input data def prepare_inputs(X_train, X_test): oe = OrdinalEncoder() oe.fit(X_train) X_train_enc = oe.transform(X_train) X_test_enc = oe.transform(X_test) return X_train_enc, X_test_enc
我們還需要準備目標變量���。
這是一個二進制分類問題����,因此我們需要將兩個類標簽映射到0和1�����。這是一種序數編碼�����,而scikit-learn提供了專門為此目的設計的LabelEncoder類����。盡管LabelEncoder設計用于編碼單個變量���,但我們可以輕松使用OrdinalEncoder并獲得相同的結果���。
所述prepare_targets()函數整數編碼的訓練集和測試集的輸出數據���。
# prepare target def prepare_targets(y_train, y_test): le = LabelEncoder() le.fit(y_train) y_train_enc = le.transform(y_train) y_test_enc = le.transform(y_test) return y_train_enc, y_test_enc
我們可以調用這些函數來準備我們的數據���。
... # prepare input data X_train_enc, X_test_enc = prepare_inputs(X_train, X_test) # prepare output data y_train_enc, y_test_enc = prepare_targets(y_train, y_test)
綜上所述���,下面列出了加載和編碼乳腺癌分類數據集的輸入和輸出變量的完整示例��。
# example of loading and preparing the breast cancer dataset from pandas import read_csv from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import OrdinalEncoder # load the dataset def load_dataset(filename): # load the dataset as a pandas DataFrame data = read_csv(filename, header=None) # retrieve numpy array dataset = data.values # split into input (X) and output (y) variables X = dataset[:, :-1] y = dataset[:,-1] # format all fields as string X = X.astype(str) return X, y # prepare input data def prepare_inputs(X_train, X_test): oe = OrdinalEncoder() oe.fit(X_train) X_train_enc = oe.transform(X_train) X_test_enc = oe.transform(X_test) return X_train_enc, X_test_enc # prepare target def prepare_targets(y_train, y_test): le = LabelEncoder() le.fit(y_train) y_train_enc = le.transform(y_train) y_test_enc = le.transform(y_test) return y_train_enc, y_test_enc # load the dataset X, y = load_dataset('breast-cancer.csv') # split into train and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # prepare input data X_train_enc, X_test_enc = prepare_inputs(X_train, X_test) # prepare output data y_train_enc, y_test_enc = prepare_targets(y_train, y_test)
現在我們已經加載并準備了乳腺癌數據集����,我們可以探索特征選擇��。
有兩種流行的特征選擇技術��,可用于分類輸入數據和分類(類)目標變量���。
他們是:
讓我們依次仔細研究每個對象���。
皮爾遜的卡方統計假設檢驗是分類變量之間獨立性檢驗的一個示例�。
您可以在教程中了解有關此統計測試的更多信息:
該測試的結果可用于特征選擇�,其中可以從數據集中刪除與目標變量無關的那些特征���。
scikit-learn機器庫在chi2()函數中提供了卡方檢驗的實現�����。此功能可用于特征選擇策略中����,例如通過SelectKBest類選擇前k個最相關的特征(最大值)���。
例如���,我們可以定義SelectKBest類以使用chi2 ()函數并選擇所有功能��,然后轉換訓練序列和測試集����。
... fs = SelectKBest(score_func=chi2, k='all') fs.fit(X_train, y_train) X_train_fs = fs.transform(X_train) X_test_fs = fs.transform(X_test)
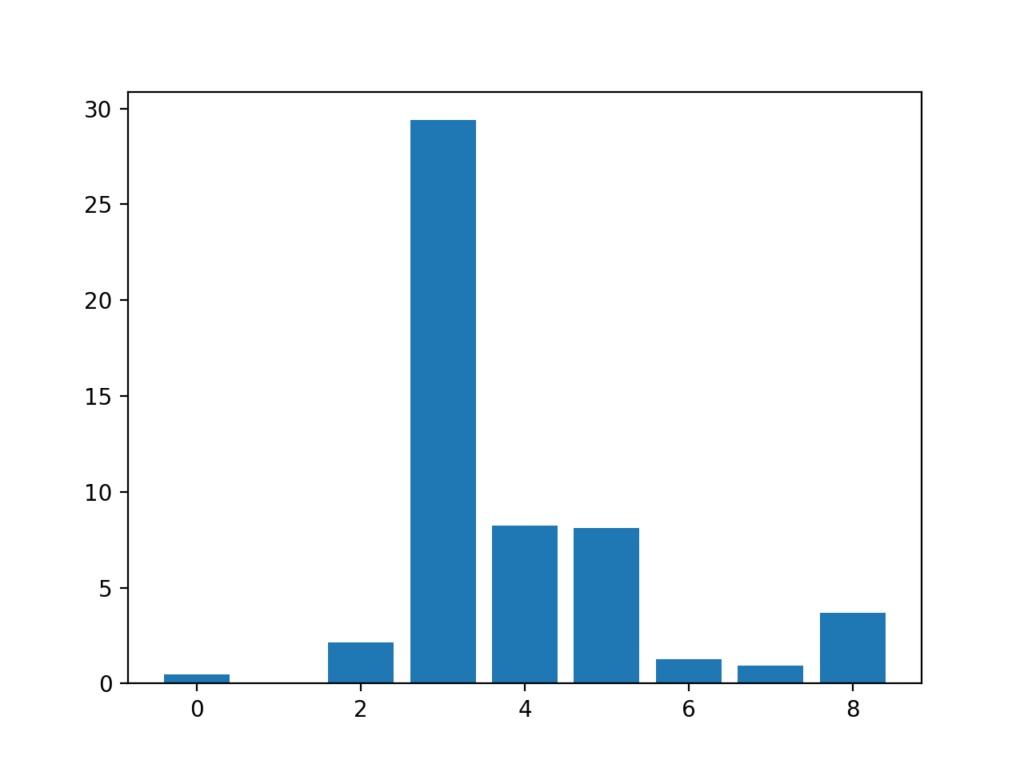
然后��,我們可以打印每個變量的分數(越大越好)���,并將每個變量的分數繪制為條形圖�����,以了解應該選擇多少個特征�����。
... # what are scores for the features for i in range(len(fs.scores_)): print('Feature %d: %f' % (i, fs.scores_[i])) # plot the scores pyplot.bar([i for i in range(len(fs.scores_))], fs.scores_) pyplot.show()
將其與上一節中乳腺癌數據集的數據準備結合在一起����,下面列出了完整的示例����。
# example of chi squared feature selection for categorical data from pandas import read_csv from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import OrdinalEncoder from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import chi2 from matplotlib import pyplot # load the dataset def load_dataset(filename): # load the dataset as a pandas DataFrame data = read_csv(filename, header=None) # retrieve numpy array dataset = data.values # split into input (X) and output (y) variables X = dataset[:, :-1] y = dataset[:,-1] # format all fields as string X = X.astype(str) return X, y # prepare input data def prepare_inputs(X_train, X_test): oe = OrdinalEncoder() oe.fit(X_train) X_train_enc = oe.transform(X_train) X_test_enc = oe.transform(X_test) return X_train_enc, X_test_enc # prepare target def prepare_targets(y_train, y_test): le = LabelEncoder() le.fit(y_train) y_train_enc = le.transform(y_train) y_test_enc = le.transform(y_test) return y_train_enc, y_test_enc # feature selection def select_features(X_train, y_train, X_test): fs = SelectKBest(score_func=chi2, k='all') fs.fit(X_train, y_train) X_train_fs = fs.transform(X_train) X_test_fs = fs.transform(X_test) return X_train_fs, X_test_fs, fs # load the dataset X, y = load_dataset('breast-cancer.csv') # split into train and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # prepare input data X_train_enc, X_test_enc = prepare_inputs(X_train, X_test) # prepare output data y_train_enc, y_test_enc = prepare_targets(y_train, y_test) # feature selection X_train_fs, X_test_fs, fs = select_features(X_train_enc, y_train_enc, X_test_enc) # what are scores for the features for i in range(len(fs.scores_)): print('Feature %d: %f' % (i, fs.scores_[i])) # plot the scores pyplot.bar([i for i in range(len(fs.scores_))], fs.scores_) pyplot.show()

首先運行示例將打印為每個輸入要素和目標變量計算的分數���。
注意:您的具體結果可能會有所不同��。嘗試運行該示例幾次����。
在這種情況下�,我們可以看到分數很小����,僅憑數字很難知道哪個功能更相關��。
也許功能3����、4���、5和8最相關�。
Feature 0: 0.472553 Feature 1: 0.029193 Feature 2: 2.137658 Feature 3: 29.381059 Feature 4: 8.222601 Feature 5: 8.100183 Feature 6: 1.273822 Feature 7: 0.950682 Feature 8: 3.699989
創建每個輸入要素的要素重要性得分的條形圖��。
這清楚地表明��,特征3可能是最相關的(根據卡方)�,并且九個輸入特征中的四個也許是最相關的����。
在配置SelectKBest來選擇這前四個功能時�����,我們可以設置k = 4 �����。
輸入要素的條形圖(x)vs Chi-Squared要素重要性(y)
互信息特征選擇
來自信息理論領域的互信息是信息增益(通常用于決策樹的構建)在特征選擇中的應用�����。
在兩個變量之間計算互信息���,并在給定另一個變量的已知值的情況下測量一個變量的不確定性降低����。
您可以在以下教程中了解有關相互信息的更多信息�。
scikit-learn機器學習庫通過commoninfoclassif()函數提供了用于信息選擇的互信息實現���。
像chi2()一樣��,它可以用于SelectKBest特征選擇策略(和其他策略)中����。
# feature selection def select_features(X_train, y_train, X_test): fs = SelectKBest(score_func=mutual_info_classif, k='all') fs.fit(X_train, y_train) X_train_fs = fs.transform(X_train) X_test_fs = fs.transform(X_test) return X_train_fs, X_test_fs, fs
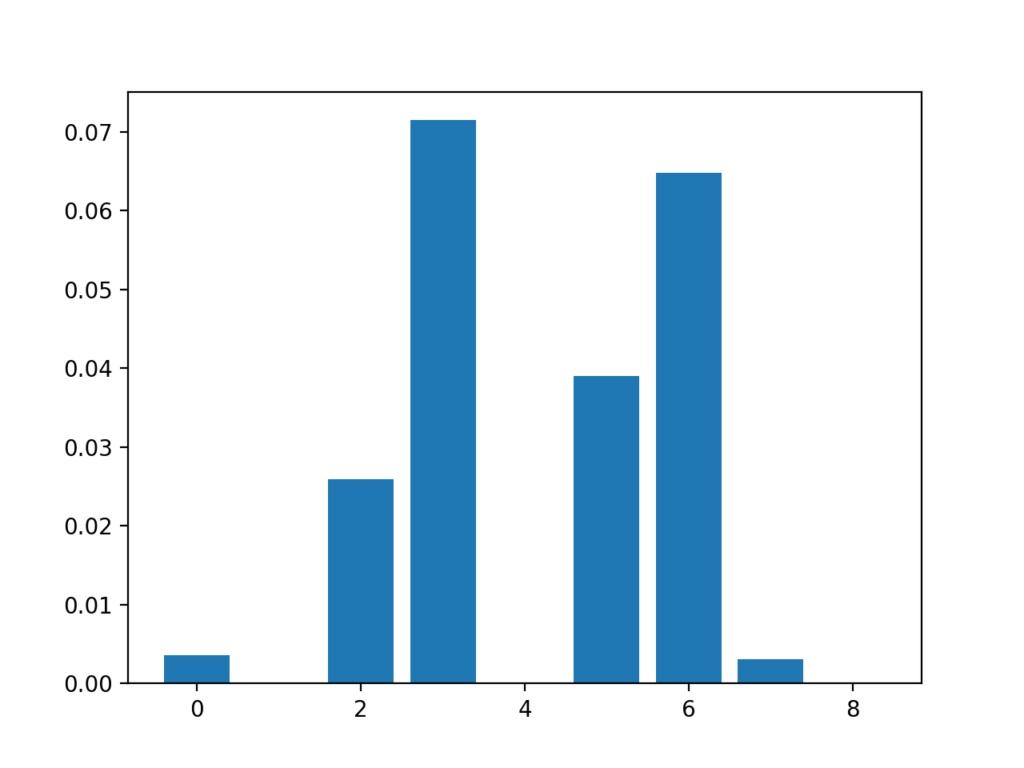
我們可以使用關于乳腺癌組的相互信息來進行特征選擇��,并像上一節中那樣打印和繪制分數(越大越好)�。
下面列出了使用互信息進行分類特征選擇的完整示例�����。
# example of mutual information feature selection for categorical data from pandas import read_csv from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import OrdinalEncoder from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import mutual_info_classif from matplotlib import pyplot # load the dataset def load_dataset(filename): # load the dataset as a pandas DataFrame data = read_csv(filename, header=None) # retrieve numpy array dataset = data.values # split into input (X) and output (y) variables X = dataset[:, :-1] y = dataset[:,-1] # format all fields as string X = X.astype(str) return X, y # prepare input data def prepare_inputs(X_train, X_test): oe = OrdinalEncoder() oe.fit(X_train) X_train_enc = oe.transform(X_train) X_test_enc = oe.transform(X_test) return X_train_enc, X_test_enc # prepare target def prepare_targets(y_train, y_test): le = LabelEncoder() le.fit(y_train) y_train_enc = le.transform(y_train) y_test_enc = le.transform(y_test) return y_train_enc, y_test_enc # feature selection def select_features(X_train, y_train, X_test): fs = SelectKBest(score_func=mutual_info_classif, k='all') fs.fit(X_train, y_train) X_train_fs = fs.transform(X_train) X_test_fs = fs.transform(X_test) return X_train_fs, X_test_fs, fs # load the dataset X, y = load_dataset('breast-cancer.csv') # split into train and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # prepare input data X_train_enc, X_test_enc = prepare_inputs(X_train, X_test) # prepare output data y_train_enc, y_test_enc = prepare_targets(y_train, y_test) # feature selection X_train_fs, X_test_fs, fs = select_features(X_train_enc, y_train_enc, X_test_enc) # what are scores for the features for i in range(len(fs.scores_)): print('Feature %d: %f' % (i, fs.scores_[i])) # plot the scores pyplot.bar([i for i in range(len(fs.scores_))], fs.scores_) pyplot.show()
首先運行示例將打印為每個輸入要素和目標變量計算的分數�����。
注意:您的具體結果可能會有所不同��。嘗試運行該示例幾次�。
在這種情況下��,我們可以看到某些功能的得分很低�,表明也許可以將其刪除�����。
也許功能3�����、6�����、2和5最相關��。
Feature 0: 0.003588 Feature 1: 0.000000 Feature 2: 0.025934 Feature 3: 0.071461 Feature 4: 0.000000 Feature 5: 0.038973 Feature 6: 0.064759 Feature 7: 0.003068 Feature 8: 0.000000
創建每個輸入要素的要素重要性得分的條形圖�����。
重要的是�����,促進了特征的不同混合���。
輸入要素的條形圖(x)vs互信息特征的重要性(y)
既然我們知道如何針對分類預測建模問題對分類數據執行特征選擇��,那么我們可以嘗試使用選定的特征開發模型并比較結果��。
使用選定特征建模
有許多不同的技術可用來對特征評分和根據分數選擇特征��。您怎么知道要使用哪個��?
一種可靠的方法是使用不同的特征選擇方法(和特征數量)評估模型��,然后選擇能夠產生最佳性能的模型的方法��。
在本節中���,我們將評估具有所有要素的Logistic回歸模型���,并將其與通過卡方選擇的要素和通過互信息選擇的要素構建的模型進行比較��。
邏輯回歸是測試特征選擇方法的良好模型��,因為如果從模型中刪除了不相關的特征����,則邏輯回歸性能會更好�。
使用所有功能構建的模型
第一步����,我們將使用所有可用功能評估LogisticRegression模型�。
該模型適合訓練數據集�,并在測試數據集上進行評估��。
下面列出了完整的示例�。
# evaluation of a model using all input features from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import OrdinalEncoder from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score # load the dataset def load_dataset(filename): # load the dataset as a pandas DataFrame data = read_csv(filename, header=None) # retrieve numpy array dataset = data.values # split into input (X) and output (y) variables X = dataset[:, :-1] y = dataset[:,-1] # format all fields as string X = X.astype(str) return X, y # prepare input data def prepare_inputs(X_train, X_test): oe = OrdinalEncoder() oe.fit(X_train) X_train_enc = oe.transform(X_train) X_test_enc = oe.transform(X_test) return X_train_enc, X_test_enc # prepare target def prepare_targets(y_train, y_test): le = LabelEncoder() le.fit(y_train) y_train_enc = le.transform(y_train) y_test_enc = le.transform(y_test) return y_train_enc, y_test_enc # load the dataset X, y = load_dataset('breast-cancer.csv') # split into train and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # prepare input data X_train_enc, X_test_enc = prepare_inputs(X_train, X_test) # prepare output data y_train_enc, y_test_enc = prepare_targets(y_train, y_test) # fit the model model = LogisticRegression(solver='lbfgs') model.fit(X_train_enc, y_train_enc) # evaluate the model yhat = model.predict(X_test_enc) # evaluate predictions accuracy = accuracy_score(y_test_enc, yhat) print('Accuracy: %.2f' % (accuracy*100))
運行示例將在訓練數據集上打印模型的準確性���。
注意:根據學習算法的隨機性����,您的特定結果可能會有所不同�����。嘗試運行該示例幾次���。
在這種情況下�,我們可以看到該模型實現了約75%的分類精度��。
我們寧愿使用能夠實現比此更好或更高的分類精度的功能子集�。
Accuracy: 75.79

使用卡方特征構建的模型
我們可以使用卡方檢驗對特征進行評分并選擇四個最相關的特征���。
下面的select_features()函數已更新以實現此目的��。
# feature selection def select_features(X_train, y_train, X_test): fs = SelectKBest(score_func=chi2, k=4) fs.fit(X_train, y_train) X_train_fs = fs.transform(X_train) X_test_fs = fs.transform(X_test) return X_train_fs, X_test_fs
下面列出了使用這種特征選擇方法評估邏輯回歸模型擬合和對數據進行評估的完整示例�����。
# evaluation of a model fit using chi squared input features from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import OrdinalEncoder from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import chi2 from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score # load the dataset def load_dataset(filename): # load the dataset as a pandas DataFrame data = read_csv(filename, header=None) # retrieve numpy array dataset = data.values # split into input (X) and output (y) variables X = dataset[:, :-1] y = dataset[:,-1] # format all fields as string X = X.astype(str) return X, y # prepare input data def prepare_inputs(X_train, X_test): oe = OrdinalEncoder() oe.fit(X_train) X_train_enc = oe.transform(X_train) X_test_enc = oe.transform(X_test) return X_train_enc, X_test_enc # prepare target def prepare_targets(y_train, y_test): le = LabelEncoder() le.fit(y_train) y_train_enc = le.transform(y_train) y_test_enc = le.transform(y_test) return y_train_enc, y_test_enc # feature selection def select_features(X_train, y_train, X_test): fs = SelectKBest(score_func=chi2, k=4) fs.fit(X_train, y_train) X_train_fs = fs.transform(X_train) X_test_fs = fs.transform(X_test) return X_train_fs, X_test_fs # load the dataset X, y = load_dataset('breast-cancer.csv') # split into train and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # prepare input data X_train_enc, X_test_enc = prepare_inputs(X_train, X_test) # prepare output data y_train_enc, y_test_enc = prepare_targets(y_train, y_test) # feature selection X_train_fs, X_test_fs = select_features(X_train_enc, y_train_enc, X_test_enc) # fit the model model = LogisticRegression(solver='lbfgs') model.fit(X_train_fs, y_train_enc) # evaluate the model yhat = model.predict(X_test_fs) # evaluate predictions accuracy = accuracy_score(y_test_enc, yhat) print('Accuracy: %.2f' % (accuracy*100))
運行示例將報告使用卡方統計量選擇的九個輸入要素中只有四個要素的模型性能�����。
注意:根據學習算法的隨機性�����,您的特定結果可能會有所不同����。嘗試運行該示例幾次�。
在這種情況下�����,我們看到該模型的準確度約為74%�,性能略有下降���。
實際上��,某些已刪除的功能可能會直接增加價值�,或者與所選功能一致�����。
在這個階段��,我們可能更喜歡使用所有輸入功能�����。
Accuracy: 74.74
使用互信息功能構建的模型
我們可以重復實驗��,并使用相互信息統計量選擇前四個功能�����。
下面列出了實現此目的的select_features()函數的更新版本�����。
# feature selection def select_features(X_train, y_train, X_test): fs = SelectKBest(score_func=mutual_info_classif, k=4) fs.fit(X_train, y_train) X_train_fs = fs.transform(X_train) X_test_fs = fs.transform(X_test) return X_train_fs, X_test_fs
下面列出了使用互信息進行特征選擇以擬合邏輯回歸模型的完整示例�。
# evaluation of a model fit using mutual information input features from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import OrdinalEncoder from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import mutual_info_classif from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score # load the dataset def load_dataset(filename): # load the dataset as a pandas DataFrame data = read_csv(filename, header=None) # retrieve numpy array dataset = data.values # split into input (X) and output (y) variables X = dataset[:, :-1] y = dataset[:,-1] # format all fields as string X = X.astype(str) return X, y # prepare input data def prepare_inputs(X_train, X_test): oe = OrdinalEncoder() oe.fit(X_train) X_train_enc = oe.transform(X_train) X_test_enc = oe.transform(X_test) return X_train_enc, X_test_enc # prepare target def prepare_targets(y_train, y_test): le = LabelEncoder() le.fit(y_train) y_train_enc = le.transform(y_train) y_test_enc = le.transform(y_test) return y_train_enc, y_test_enc # feature selection def select_features(X_train, y_train, X_test): fs = SelectKBest(score_func=mutual_info_classif, k=4) fs.fit(X_train, y_train) X_train_fs = fs.transform(X_train) X_test_fs = fs.transform(X_test) return X_train_fs, X_test_fs # load the dataset X, y = load_dataset('breast-cancer.csv') # split into train and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # prepare input data X_train_enc, X_test_enc = prepare_inputs(X_train, X_test) # prepare output data y_train_enc, y_test_enc = prepare_targets(y_train, y_test) # feature selection X_train_fs, X_test_fs = select_features(X_train_enc, y_train_enc, X_test_enc) # fit the model model = LogisticRegression(solver='lbfgs') model.fit(X_train_fs, y_train_enc) # evaluate the model yhat = model.predict(X_test_fs) # evaluate predictions accuracy = accuracy_score(y_test_enc, yhat) print('Accuracy: %.2f' % (accuracy*100))
運行示例使模型適合于使用互信息選擇的前四個精選功能���。
注意:根據學習算法的隨機性��,您的特定結果可能會有所不同��。嘗試運行該示例幾次���。
在這種情況下��,我們可以看到分類精度小幅提升至76%�����。
為了確保效果是真實的�,最好將每個實驗重復多次并比較平均效果���。探索使用k倍交叉驗證而不是簡單的訓練/測試拆分也是一個好主意��。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情�;














 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
