
CDA數據分析師 出品
作者:Mika
數據:真達
后期:澤龍
【導語】:這幾天吃的最多的就屬騰訊狀告老干媽的瓜了��,事件頻頻反轉��,讓網友們在瓜地里吃都吃不過來�。今天我們就來用數據聊一聊�。Python技術分析請看第四部分�。
Show me data��,用數據說話
今天我們聊一聊 騰訊老干媽這場“逗鵝冤”
點擊下方視頻�����,先睹為快:
這幾天吃的最多的就屬騰訊狀告老干媽的瓜了��,事件頻頻反轉�,讓網友們在瓜地里吃都吃不過來���。
一邊是財大氣粗的鵝廠��,另一邊是國內最火辣的“國民女神”��,看似毫無交集的雙方又是怎么一回事呢?

事情是這樣的�,6 月 30 日�����,有消息稱���,騰訊把老干媽給告了!理由是老干媽拖欠騰訊廣告費�����,總額約 1600w����。吃瓜群眾一片嘩然�,那個女人竟然吃霸王餐!
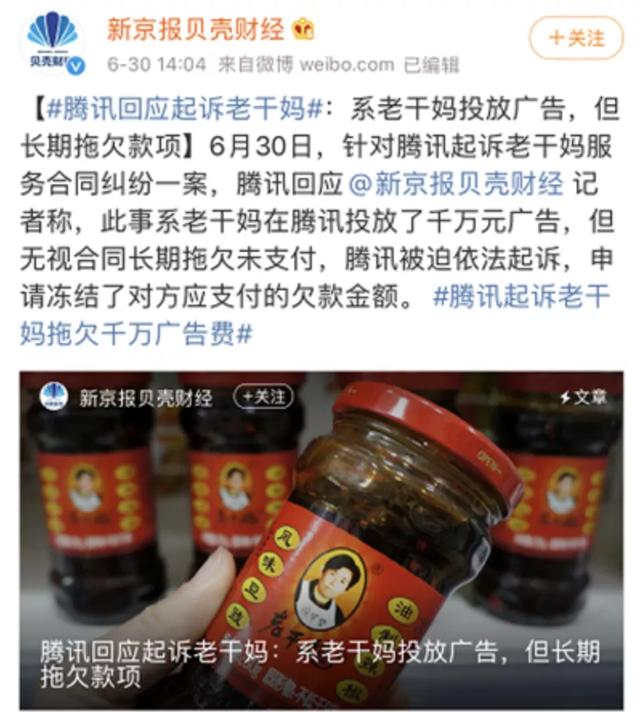
誰知道���,不到一天��,這件事情就了反轉���。6月30日晚間���,老干媽聲稱從沒和騰訊合作過���,騰訊被騙了�,還嚴肅地發了個聲明����,并幫騰訊報了警���。

一時間����,鵝說鵝有理��,媽說媽有理���。
接著7月1日�����,貴陽警方也發布通報���,概括一下就是:3 個騙子為了倒賣騰訊游戲禮包碼�,冒充老干媽的市場人員與騰訊簽了合同��。

消息出來���,網友們都驚了�,騰訊居然有被騙的一天?
與此同時騰訊的公關也沒閑著����,開始一系列雷厲風行的自黑操作���,還表示要一千瓶老干媽全網尋騙子�����,老干媽也是迅速上架1000瓶大客戶組合裝辣椒醬���,就是這么霸氣����。
那這次騰訊都有哪些自黑操作?
老干媽的辣椒到底香不香?
今天我們就用數據來盤一盤����。
主要從以下幾點展開:
“吃了假辣椒醬的憨憨企鵝” 官方自黑最為致命
辣椒醬又香了!這些年乘風破浪的老干媽
吃了這么多年的老干媽,究竟哪種口味最好吃?
教你用Python分析B站“逗鵝冤”視頻數據
01“吃了假辣椒醬的憨憨企鵝”
官方自黑最為致命
騰訊的公關也沒閑著��,一系列雷厲風行的自黑操作�����。先是于7月1日中午���,騰訊官方在B站動態發布騰訊官方B站賬號發表動態:“今天中午的辣椒醬突然不香了��?!?
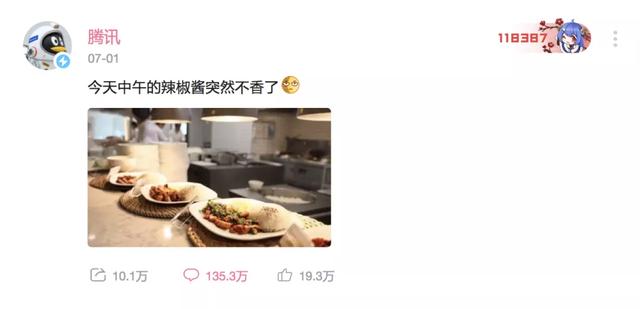
評論區馬上成了大廠們的狂歡區��, 各大品牌紛紛趕來嘲笑被騙的鵝廠��,順便給自己打個廣告���、蹭波熱度�����。
隔壁的阿里秉承著看熱鬧不嫌事大的原則�����,開始整起了活——希望天下無假章����。

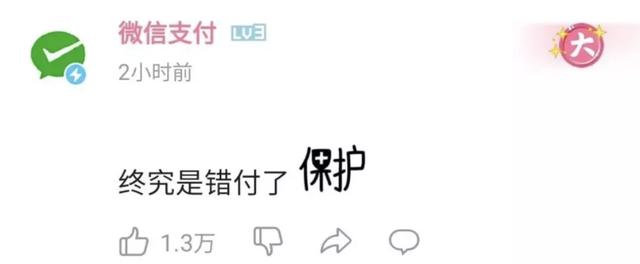
只有微信支付一臉惆悵�,發出一聲感慨: 還是錯付了���。
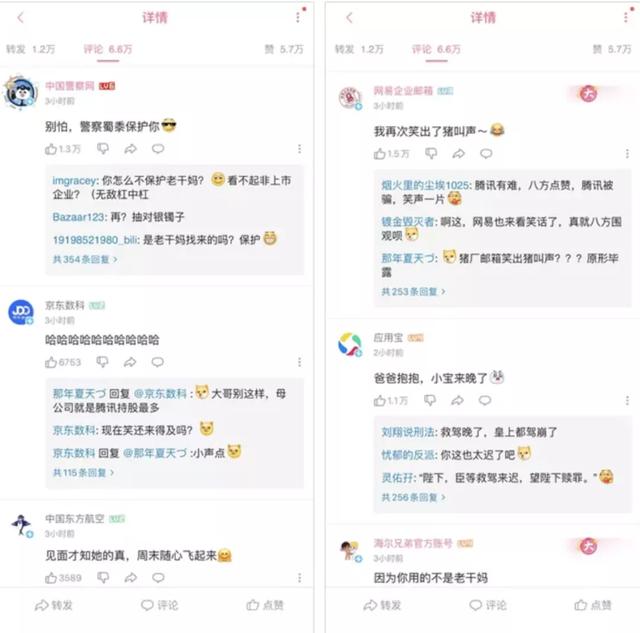
京東數科則是無情的哈哈哈��,網易郵箱笑出豬叫�。
騰訊自己也干脆破罐子破摔��,用一千瓶老干媽作為網友提供線索的獎勵���。

當晚��,騰訊再發視頻自黑�����,承認自己就是那個吃了假辣椒醬的憨憨企鵝��。目前截止到發稿�,這條視頻在b站最高全站排名第三���,播放量高達602.萬����,共5.6萬條彈幕���。

瞬時間���,騰訊和老干媽這個事件一出��,B站上也涌現出了很多相關視頻���。
讓我們對數據進行進一步分析整理:
(Python分析B站視頻講解請看第四部分)
相關視頻發布時間分布
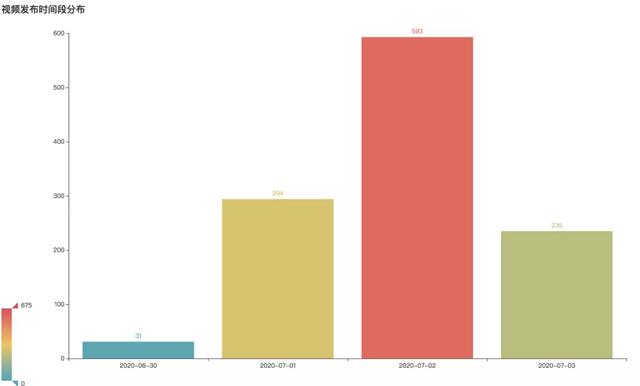
可以看到��,當事件剛爆出的6月30日有31個視頻���,不算多�����。到7月1日��,有294個相關視頻���,隨著進一步發酵升溫�,7月2日已新發布593個視頻���,而這一數據也還在增加�。
那么這些衍生的視頻都屬于什么類型分區呢?
視頻分區分布
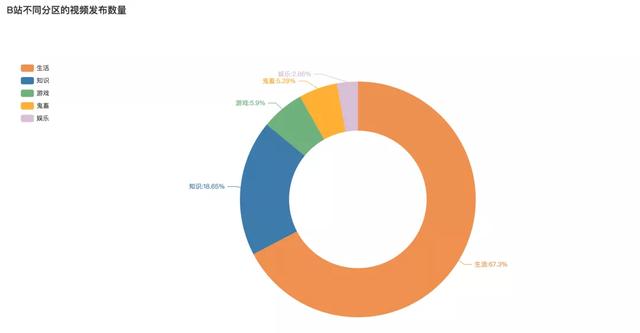
可以看到����,生活區的最多�,占比67.3%�。其次知識類的占比18.65%���。
這些視頻中哪些播放量最高?
播放量TOP10視頻
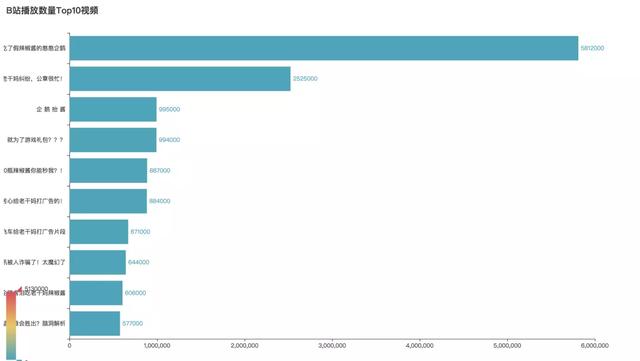
關于這個事件��,騰訊官方發布的《我就是那個吃了假辣椒醬的憨憨企鵝》播放量最高�����,截止到發稿止��,播放量已突破600萬次���,果然官方自黑最為致命��。然后是羅翔老師的《老干媽糾紛���,公章很忙》���,位居第二�����,從法律角度帶你硬核科普吃瓜��。
視頻標題詞云

這些視頻都在說些啥?通過分析相關視頻標題詞云可以看到�,關鍵字中除了"騰訊"���、"老干媽"����、"企鵝"�、"逗鵝冤"��、"辣椒醬"等都是圍繞的焦點���。
02辣椒醬到底香不香�����?
這些年乘風破浪的老干媽
如果提到家家戶戶必備的調料神器�,那老干媽絕對當之無愧���。多年來一直不變的紅色包裝��,擰開瓶蓋�,麻辣紅油的香氣就四溢開來���,火紅的辣椒中伴著或是豆豉��、肉絲的醬料簡直是絕妙的下飯神器��。
全國辣椒醬市場份額將近400億元���,老干媽獨占了10%�,可見老干媽在國人心中有著舉足輕重的地位��。根據數據顯示��,老干媽一天的銷售量為160萬瓶�����,2019年老干媽的銷售額突破50億元�����,15年之內老干媽的生產總值增加了80多倍����。
近年來�����,老干媽也是各種玩跨界營銷:
2018年9月��,紐約時裝周上����,老干媽衛衣亮相T臺引關注��。

聯手《男人裝》�,以“火辣教母”為噱頭推出定制禮盒����。

以及定制手提袋:

還聯合聚劃算拍了視頻廣告���,外形神似“老干媽”陶華碧的年輕女孩���,配上“擰開干媽���,看穿一切”的洗腦歌詞�,再加上鬼畜舞蹈��,瞬間吸睛無數�����。

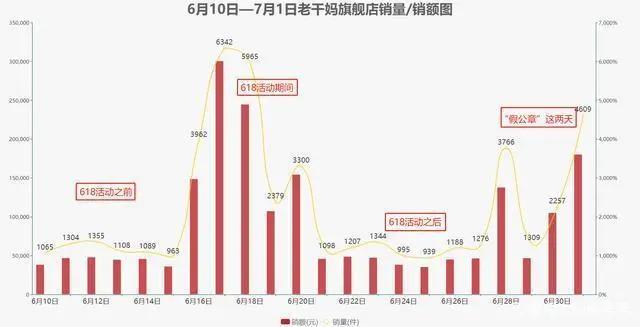
雖然近年來���,由于各種網紅辣醬輪番登場�,老干媽的銷量不太如意��。自從6月30日“逗鵝冤”事件爆發出來后��,讓老干媽又重新活了起來�,銷量出現了大幅度突破��,有種”大圣歸來“的感覺���。老干媽一躍成為了近期飆升最快的店鋪���。網友感嘆:老干媽又香了�。
03吃了這么多年的老干媽
究竟哪種口味最好吃�����?
那么吃了這么多年的老干媽��,究竟哪種口味最好吃呢?我們分析了老干媽天貓旗艦店的數據��。分析淘寶數據的方法��,我們之前有講到����,歡迎回顧之前的文章:
Python告訴你:粽子甜咸之爭誰勝出?吃貨最愛買誰家的粽子?
首先看到價格:
老干媽商品價格分布
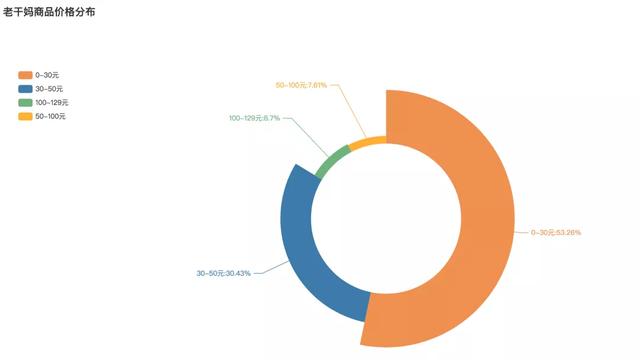
在售價方面���,老干媽辣醬既有單瓶銷售的�,也有幾瓶的組合裝�����?��?梢钥吹狡渲?0元以內的產品是最多的���,占比近一半��,為53.26%�。其次30-50元的位30.43%���。
商品標題詞云
接下來看到商品的標題�����,

可以看到除了經典的"老干媽風味"�、"辣椒醬"�����、"香辣"�、"豆豉"�����、"拌面"等都是常常出現的詞��。
最后看到最關鍵的�,那種口味最受歡迎呢?
不同口味銷量分布
說道老干媽的口味���,那可就多了��。除了最熟悉的風味豆豉�����,還有風味油辣椒�、風味辣子雞����、辣豆瓣�、干煸肉絲等十多種口味�����。當中哪些口味最受青睞呢?
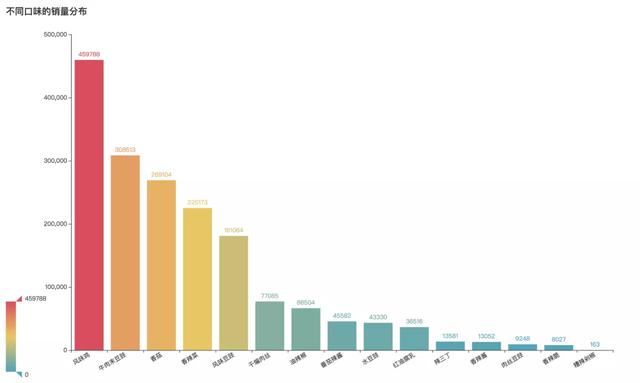
根據老干媽天貓旗艦店的銷售數據���,讓我們看到銷量口味排名圖:
其中銷的最好的就是風味雞這款啦���,銷量遙遙領先��。之后第二名的是牛肉末豆豉這款�����。香菇和香辣菜分別位居三�����、四名��。之后經典的風味豆豉和干煸肉絲分別為第五���、第六�。
那么哪款老干媽又是你的最愛呢?歡迎留言告訴我們哦~
04教你用Python分析
B站視頻數據
最后我們看下如何分析B站的視頻數據�。
回復關鍵字“老干媽”
獲取詳細數據代碼
我們使用Python獲取了B站上關于騰訊-老干媽相關的視頻數據����,進行了數據分析�。
首先導入所需庫����,其中pandas用于數據讀入和數據清洗�,pyecharts用于數據可視化����,stylecloud用于繪制詞云圖���。
# 導入包
import pandas as pd
import jieba
import re
from pyecharts.charts import Bar, Line, Pie, Map, Page
from pyecharts import options as opts
from pyecharts.globals import SymbolType, WarningType
WarningType.ShowWarning = False
import stylecloud
from IPython.display import Image # 用于在jupyter lab中顯示本地圖片
1. 數據讀入
首先讀入數據���。
# 讀入數據
df = pd.read_excel('../data/B站分區視頻7.03.xlsx')
df.head()

去重之后查看一下數據集的大小�����,一共有1222條數據��。
# 去重
df = df.drop_duplicates()
# 刪除列
df.drop('video_url', axis=1. inplace=True)
df.info()
Int64Index: 1222 entries, 0 to 1406
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 region 1222 non-null object
1 title 1222 non-null object
2 upload_time 1222 non-null object
3 view_num 1222 non-null object
4 up_author 1222 non-null object
dtypes: object(5)
memory usage: 57.3+ KB
2. 數據預處理
數據預處理部分主要進行以下部分工作:
view_num:提取數值和單位���,轉換為數值型;
篩選6.30~7.03數據
# 提取數值
df['num'] = df['view_num'].str.extract('(\d+.*\d+)').astype('float')
# 提取單位
df['unit'] = df['view_num'].str.extract('([\u4e00-\u9fa5]+)')
df['unit'] = df['unit'].replace('萬', 10000).replace(np.nan, 1)
# 計算乘積
df['true_num'] = df['num'] * df['unit']
# 刪除列
df.drop('view_num', axis=1. inplace=True)
# 篩選時間
pattern = re.compile('2020-06-30|2020-07-01|2020-07-02|2020-07-03')
df = df[df.upload_time.str.contains(pattern)]
3. 數據可視化
我們針對數據進行描述性統計分析����,探索一下問題:
發布時間和熱度
不同分區的發布數量
不同分區的播放量表現
最高播放的Top10視頻
標題詞云圖�����。
3.1 發布時間和熱度
time_num = df.upload_time.value_counts().sort_index()
time_num
2020-06-30 31
2020-07-01 294
2020-07-02 593
2020-07-03 235
Name: upload_time, dtype: int64
# 條形圖
bar1 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar1.add_xaxis(time_num.index.tolist())
bar1.add_yaxis('', time_num.values.tolist())
bar1.set_global_opts(title_opts=opts.TitleOpts(title='視頻發布時間段分布'),
visualmap_opts=opts.VisualMapOpts(max_=675),
)
bar1.render()
3.2 不同分區的發布數量
region_num = df.region.value_counts()
region_num
生活 776
知識 215
游戲 68
鬼畜 61
娛樂 33
Name: region, dtype: int64
data_pair = [list(z) for z in zip(region_num.index.tolist(), region_num.values.tolist())]
# 繪制餅圖
pie1 = Pie(init_opts=opts.InitOpts(width='1350px', height='750px'))
pie1.add('', data_pair, radius=['35%', '60%'])
pie1.set_global_opts(title_opts=opts.TitleOpts(title='B站不同分區的視頻發布數量'),
legend_opts=opts.LegendOpts(orient='vertical', pos_top='15%', pos_left='2%'))
pie1.set_series_opts(label_opts=opts.LabelOpts(formatter="��:{d}%"))
pie1.set_colors(['#EF9050', '#3B7BA9', '#6FB27C', '#FFAF34', '#D8BFD8'])
pie1.render()
3.3 不同分區的播放量表現
region_view = df.groupby('region')['true_num'].sum()
region_view = region_view.sort_values(ascending=False)
region_view
region
生活 12760197.0
知識 7167597.0
鬼畜 1382580.0
游戲 792650.0
娛樂 53831.0
Name: true_num, dtype: float64
# 條形圖
bar2 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar2.add_xaxis(region_view.index.tolist())
bar2.add_yaxis('', region_view.values.tolist())
bar2.set_global_opts(title_opts=opts.TitleOpts(title='B站不同分區的視頻播放總量'),
visualmap_opts=opts.VisualMapOpts(max_=10837810.0),
)
bar2.render()
3.4 最高播放的Top10
# 最多播放top10
view_top10 = df.sort_values('true_num', ascending=False).head(10)[['title', 'true_num']]
view_top10 = view_top10.sort_values('true_num')
view_top10

# 柱形圖
bar3 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar3.add_xaxis(view_top10.title.values.tolist())
bar3.add_yaxis('', view_top10.true_num.values.tolist())
bar3.set_global_opts(title_opts=opts.TitleOpts(title='B站播放數量Top10視頻'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(position='inside')),
visualmap_opts=opts.VisualMapOpts(max_=5130000.0),
)
bar3.set_series_opts(label_opts=opts.LabelOpts(position='right'))
bar3.reversal_axis()
bar3.render()
3.5 標題詞云圖
# 繪制詞云圖
stylecloud.gen_stylecloud(text=' '.join(text), # text為分詞后的字符串
collocations=False,
font_path=r'?C:\Windows\Fonts\msyh.ttc',
icon_name='fas fa-bell',
size=653.
output_name='./詞云圖/B站分區視頻標題詞云圖.png')
Image(filename='./詞云圖/B站分區視頻標題詞云圖.png')
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
