前面文章小編簡單給大家介紹了泛化能力的一些基礎知識�����,今天給大家帶來的是提高模型泛化能力的方法--正則化���。
一���、首先來回顧一下什么是泛化能力
泛化能力(generalization ability)��,百科給出的定義是:機器學習算法對新鮮樣本的適應能力��。學習的目的是學到隱含在數據對背后的規律�����,對具有同一規律的學習集以外的數據����,經過訓練的網絡也能給出合適的輸出���,該能力稱為泛化能力�����。簡單來概括一下�����,泛化能力就是一個機器學習算法能夠識別沒有見過的樣本的能力���,通俗點說就是學以致用����,舉一反三的能力���。機器學習方法訓練出一個模型����,我們會希望這個模型不但是對于已知的數據(訓練集)性能表現良好�����,而且對于未知的數據(測試集)也能夠表現良好����,這就表明這個模型具有良好的泛化能力�。在實際應用子中���,模型的過擬合(overfitting)與欠擬合(underfitting)能夠最直觀的體現出泛化能力的好壞��。
根據泛化能力強弱���,可以分為:
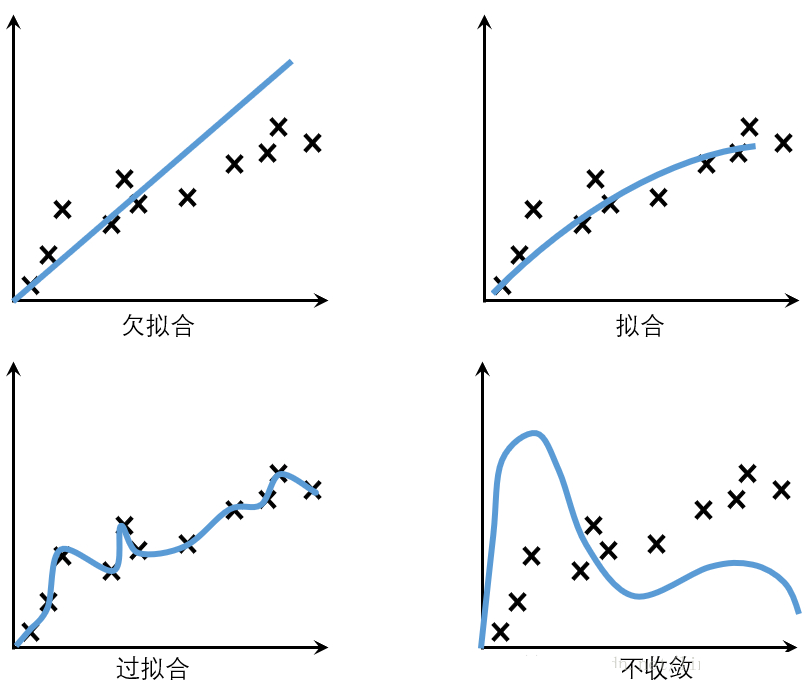
欠擬合:模型不能在訓練集上獲得足夠低的誤差;
擬合:測試誤差與訓練誤差差距較小;
過擬合:訓練誤差和測試誤差之間的差距太大;
不收斂:模型不是根據訓練集訓練得到的�����。
二�����、簡單介紹正則化
正則化regularization的目標為:模型的經驗風險和模型復雜度之和達到最小�����,即結構風險達到最小����。也就是正則化的目的是為了防止過擬合���, 從而增強泛化能力��。
我們通常將正則化定義為:對學習算法的修改���,目的是減少泛化誤差而不是訓練誤差
在訓練次數足夠多��,以及表達形式足夠復雜的情況下���,訓練誤差能夠無限小��,可是這并不代表著泛化誤差的減小�。相反的��,一般情況下��,這樣會導致泛化誤差的增大����。最常見的例子是:真實數據的分布符合二次函數�����,但是欠擬合一般會將模型擬合成一次函數����,而過擬合通常將模型擬合成高次函數�。根據奧卡姆剃須原則:在盡可能符合數據原始分布的基礎上���,更加平滑����、簡單的模型�����,往往更加符合數據的真實特征��。所以�����,我們必須采用采用某種約束���,這也就引出了的正則化��。
三��、正則化---提高模型的泛化能力
按策略正則化可以分為以下三類:
(一) 經驗正則化:利用工程上的技巧�����,實現更低的泛化誤差�,例如:提前終止法�、模型集成���、Dropout等;
1.提前終止(earlystop)
一種最簡單的正則化方法�����,在泛化誤差指標不再提升后��,提前結束訓練
2.模型集成(ensemable))
通過訓練多個模型來完成該任務�����,這些模型可以是不同的網絡結構��,不同的初始化方法�,不同的數據集訓練出來的��,也可以是采用不同的測試圖片處理方法���?����?偨Y來說就是�����,利用多個模型進行投票的策略
3.Dropout移除一部分神經元
Dropout采用的是"綜合起來取平均”的策略�����,來防止過擬合問題����。不同的網絡會產生不同的過擬合問題����,取平均會讓一些“相反的”擬合有互相抵消的可能��,整個Dropout過程就相當于 對很多個不同的神經網絡取平均����。而且因為dropout程序導致兩個神經元不一定每次都在一個dropout網絡中出現�,這樣會減少神經元之間復雜的共適應關系
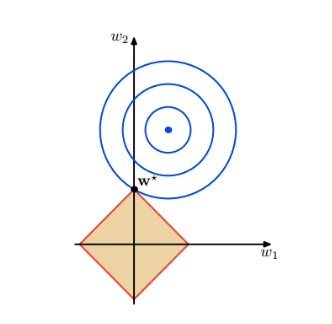
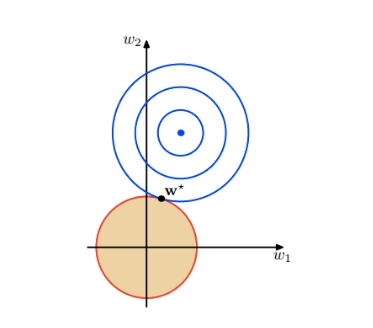
(二)參數正則化:直接提供正則化約束��,例如:L1/L2正則化法等;
L1/L2正則化方法���,就是最常用的正則化方法���,它直接來自于傳統的機器學習�。
L1正則化: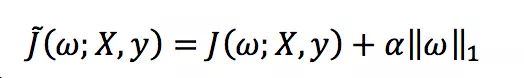
L2正則化: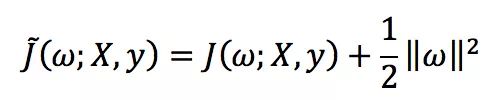
(三)隱式正則化:不直接提供約束�,例如:數據有關的操作�,包括歸一化��、數據增強��、擾亂標簽等����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
