近來數據記錄和規模屬性都在急劇增長����,由于大多數數據挖掘算法都是直接逐列處理數據�����,因此導致算法越來越慢�����。為了保證減少數據列數的同時�,丟失的數據信息盡可能少�,
數據降維處理算法應運而生�。
一�、降維的概念和本質
機器學習領域中的降維就是指采用某種映射方法�,將原高維空間中的數據點映射到低維度的空間中��。降維的本質是學習一個映射函數 f : x->y�����,其中x是原始數據點的表達�,目前最多使用向量表達形式���。 y是數據點映射后的低維向量表達�����,通常y的維度小于x的維度(當然提高維度也是可以的)�����。
二�����、降維的作用:
1.降低時間復雜度和空間復
2.節省了提取不必要特征的開銷
3.去掉數據集中夾雜的噪音
5.較簡單的模型在小數據集上有更強的魯棒性
6.當數據能有較少的特征進行解釋��,我們可以更好 的解釋數據�,使得我們可以提取知識�����。
7.實現數據可視化
三����、常用的降維方法
1.PCA
PCA是不考慮樣本類別輸出的無監督降維技術����。
PCA的算法步驟:
設有m條n維數據�。
1)將原始數據按列組成n行m列矩陣X
2)將X的每一行(代表一個屬性字段)進行零均值化��,即減去這一行的均值
3)求出協方差矩陣
4)求出協方差矩陣的特征值及對應的特征向量
5)將特征向量按對應特征值大小從上到下按行排列成矩陣�����,取前k行組成矩陣P
6)即為降維到k維后的數據
2.LDA
LDA是一種監督學習的降維技術����,也就是說它的數據集的每個樣本是有類別輸出的��。這點和PCA不同���。LDA的思想可以用一句話概括���,就是“投影后類內方差最小���,類間方差最大”�。什么意思呢? 我們要將數據在低維度上進行投影���,投影后希望每一種類別數據的投影點盡可能的接近�,而不同類別的數據的類別中心之間的距離盡可能的大�����。
LDA算法步驟:
1) 計算類內散度矩陣
2) 計算類間散度矩陣
3) 計算矩陣
4)計算的最大的d個特征值和對應的d個特征向量,得到投影矩陣[Math Processing Error]
5) 對樣本集中的每一個樣本特征,轉化為新的樣本
6) 得到輸出樣本集
3.局部線性嵌入 (LLE)
Locally linear embedding(LLE)是一種非線性降維算法�,即使數據降維后��,也能較好地保持原有 流形結構 ��。LLE稱得上是流形學習方法最經典的工作之一���,后續很多的流形學習�����、降維方法都與LLE有密切聯系�����。
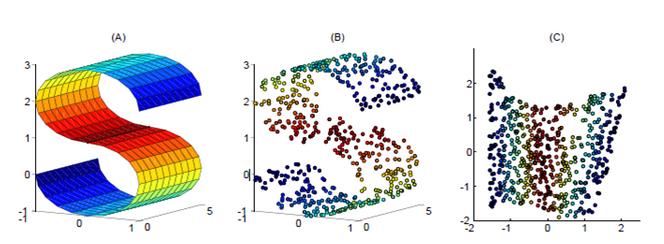
如下圖�����,使用LLE將三維數據(b)映射到二維(c)之后���,映射后的數據仍能保持原有的數據流形(紅色的點互相接近���,藍色的也互相接近)�����,說明LLE有效地保持了數據原有的流行結構�。
但是LLE在有些情況下也并不適用���,如果數據分布在整個封閉的球面上��,LLE則不能將它映射到二維空間����,且不能保持原有的數據流形���。那么我們在處理數據中�����,首先假設數據不是分布在閉合的球面或者橢球面上�。
4.拉普拉斯特征映射(Laplacian Eigenmaps)
Laplacian Eigenmaps 是用局部的角度去構建數據之間的關系�。
使用時算法具體步驟為:
步驟1:構建圖
使用某一種方法來將所有的點構建成一個圖���,例如使用KNN算法���,將每個點最近的K個點連上邊���。K是一個預先設定的值����。
步驟2:確定權重
確定點與點之間的權重大小����,例如選用熱核函數來確定�,如果點i和點j相連�����,那么它們關系的權重設定為:

使用最小的m個非零特征值對應的特征向量作為降維后的結果輸出���。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
